编码与编码转换
UnicodeString 采用 UTF-16 编码,即使用 16 位的字符 char16_t 进行编码。
Windows 操作系统里面的 wchar_t 等同于 char16_t,而其他操作系统的 wchar_t 相当于 char32_t,
所以 UnicodeString 在 Windows 里面采用 wchar_t 编码,而在其他操作系统里面使用 char16_t 进行编码。
字节类型 - 代理对、前导代理、后尾代理
由于 UTF-16 采用 16 位的字符 char16_t 进行编码,UNICODE 的基本多语言平面 (BMP) 里面的字符,直接使用单个 char16_t 编码,编码值就等于 UNICODE 码值;而辅助平面里面的字符,使用一对 char16_t 进行编码,这一对 char16_t 称为代理对 (surrogate pair),这样的字符长度为 32 位,即 4 个字节。
辅助平面的编码空间为 0x10000 ~ 0x10FFFF,一共 1,048,576 个码位,
把这些码位的编码值都减去 0x10000,那么就是 0x0000 ~ 0xFFFFF 这个 20 位二进制长度表示的范围了,
把这 20 位的数值分成两段:高 10 位和低 10 位,他们的范围都是 0x0000 ~ 0x03FF,
高 10 位 0x0000 ~ 0x03FF 加上 0xD800 得到 0xD800 ~ 0xDBFF,称为高位代理 (high surrogate),
低 10 位 0x0000 ~ 0x03FF 加上 0xDC00 得到 0xDC00 ~ 0xDFFF,称为低位代理 (low surrogate),
高位代理和低位代理没有重复的编码,所有的高位代理的编码值都比低位代理的数值小,这些编码值正好在基本多语言平面里面的预留编码范围。
为了避免使用上的混淆,现在的 UNICODE 标准把高位代理称为前导代理 (lead surrogate),把低位代理称为后尾代理 (trail surrogate)。
根据以上的 UTF-16 编码规则,每个 char16_t 字符就有 3 种类型:
• 单个 char16_t 的基本多语言平面 (BMP) 字符,取值范围:0x0000 ~ 0xD7FF 和 0xE000 ~ 0xFFFF
• 前导代理 (lead surrogate),取值范围:0xD800 ~ 0xDBFF
• 后尾代理 (trail surrogate),取值范围:0xDC00 ~ 0xDFFF
这 3 种类型的字符没有重叠的编码值,这样就可以简单的根据取值范围来判断类型。
UnicodeString 的 ByteType 方法,返回的是每个字符的字节类型,是 UnicodeString::TStringLeadCharType 类型的,是下面表格里面的值:
| ctNotLeadChar |
这是单个 char16_t 字符,不是 UTF-16 编码的代理对 (surrogate pair) 字符。 |
| ctbLeadSurrogate |
这是 UTF-16 编码的代理对当中的前导代理 (lead surrogate) |
| ctTrailSurrogate |
这是 UTF-16 编码的代理对当中的后尾代理 (trail surrogate) |
很多软件不支持或不能正确处理代理对而引起辅助平面的文字无法正常显示或处理。
【例:获取字符串长度、字符个数、字节类型、每个字符的类型】
【例:获取字符串长度、字符个数、每个字符的类型】
字符类型 - UnicodeCategory
用函数 GetUnicodeCategory 获取字符串里面的每个字符是什么类型的,返回值是 TUnicodeCategory 枚举类型的。
【例:获取字符串长度、字符个数、字节类型、每个字符的类型】
字符个数和字节数
判断字符串里面的字符是双字节字符或是四字节字符
由于 UnicodeString 采用 UTF-16 编码,每个字符采用 1 个或 2 个 16 位的字符 (char16_t 或 wchar_t) 进行编码,
所以字符串的长度不等于字符个数。
字符串长度 = s.Length(); 即 16 位字符的个数 (char16_t 或 wchar_t)
字符串的字节数 = 字符串长度 * 2; 因为字符串是有 16 位的字符进行编码的,每个 16 位字符 2 个字节。
字符个数 = 单独字符的个数 + 代理对的个数。
UnicodeString 的 ByteType, IsLeadSurrogate 和 IsTrailSurrogate 方法可以判断字节 (字符) 的类型。
例1:获取字符串长度、字符个数、字节类型、每个字符的类型
 获取字符串长度、字符个数、字节类型、每个字符的类型 获取字符串长度、字符个数、字节类型、每个字符的类型
例2:获取字符串长度、字符个数、字节类型
void __fastcall TForm1::Button1Click(TObject *Sender)
{
UnicodeString s = L"A€δ螭𧉚😊☯";
int iLength = s.Length();
int iCharCount = 0;
Memo1->Lines->Add(L"字符串长度:" + IntToStr(iLength) + L" (个 wchar_t)");
for(int i=1; i<=iLength; i++)
{
UnicodeString::TStringLeadCharType ct = s.ByteType(i);
UnicodeString sInfo = L"s[" + IntToStr(i) + L"]: " + EnumToStr(ct);
switch(ct)
{
case UnicodeString::ctNotLeadChar :
{
iCharCount++;
sInfo += L", 第 " + IntToStr(iCharCount) + L" 个字符";
sInfo += L", 单独字符: \"" + s.SubString(i,1);
} break;
case UnicodeString::ctbLeadSurrogate:
{
iCharCount++;
sInfo += L", 第 " + IntToStr(iCharCount) + L" 个字符";
sInfo += L", 与 s[" + IntToStr(i+1) + L"] 组为: \"" + s.SubString(i,2);
} break;
case UnicodeString::ctTrailSurrogate:
{
sInfo += L", 与 s[" + IntToStr(i-1) + L"] 组合";
} break;
}
Memo1->Lines->Add(sInfo);
}
Memo1->Lines->Add(L"一共 " + IntToStr(iCharCount) + L"个字符");
} |

判断字符串里面的字符是汉字或是英文
目前的 UNICODE 9.0 版本里面的汉字:CJK 中日韩统一表意文字 (CJK Unified Ideographs) 包含 6 个区段:他们的编码范围请点击这里。
C++ Builder 里面没有找到判断某个字符是否为汉字的函数,我写了两个函数,具体代码在下面的例子里面。
int GetCjkCategory(const UnicodeString &s, int index);
获取字符串 s 里面的第 index 个编码的 CJK 分组
bool IsCjkCharacter(const UnicodeString &s, int index); 字符串 s 里面的第 index 个编码是否为汉字
例1:判断字符串里面的字符是否为汉字,获取汉字的 CJK 分组,计算代理对的 UNICODE 编码值
int GetCjkCategory(const UnicodeString &s, int index) // 获取字符串 s 里面的第 index 个编码的 CJK 分组
{
unsigned long c = s[index]; // 第 index 个编码值
if(c>=0x4E00 && c<=0x9FD5) return 0; // U+4E00 ~ U+9FD5: CJK Unified Ideographs
if(c>=0x3400 && c<=0x4DB5) return 1; // U+3400 ~ U+4DB5: CJK Unified Ideographs Extension A
if(c>=0xD800 && c<=0xDBFF) // 如果是前导代理 // s.IsLeadSurrogate(index)
{
c = 0x10000 + (((c-0xD800)<<10) | (s[index+1]-0xDC00)); // 计算代理对的 UNICODE 编码值
if(c >= 0x20000 && c <= 0x2A6D6) return 2; // U+20000 ~ U+2A6D6: CJK Unified Ideographs Extension B
if(c >= 0x2A700 && c <= 0x2B734) return 3; // U+2A700 ~ U+2B734: CJK Unified Ideographs Extension C
if(c >= 0x2B740 && c <= 0x2B81D) return 4; // U+2B740 ~ U+2B81D: CJK Unified Ideographs Extension D
if(c >= 0x2B820 && c <= 0x2CEA1) return 5; // U+2B820 ~ U+2CEA1: CJK Unified Ideographs Extension E
}
return -1; // 不是 CJK,或者是后尾代理 (不处理后尾代理)
}
bool IsCjkCharacter(const UnicodeString &s, int index) // 字符串 s 里面的第 index 个编码是否为汉字
{
return GetCjkCategory(s, index) >= 0;
} |
例2:获取字符串里面汉字的个数和第几个字符是汉字:
void __fastcall TForm1::Button2Click(TObject *Sender)
{
UnicodeString sText = L"Abcd㈤ωπ𣊫朤𨰻𣛧㵘燚㙓。ABC";
int iChineseCharCount = 0; // 汉字个数
UnicodeString sIndex; // 第几个字符是汉字
for(int i=1; i<=sText.Length(); i++)
{
if(IsCjkCharacter(sText,i)) // 如果 sText 的第 i 个字符是汉字
{
iChineseCharCount++; // 汉字个数加一
if(!sIndex.IsEmpty()) // 如果原先有内容
sIndex +=L", "; // 加上一个逗号
sIndex += IntToStr(i); // 第 i 个字符是汉字
}
}
Memo1->Lines->Add(sText);
Memo1->Lines->Add(L"一共 " + IntToStr(iChineseCharCount) + L" 个汉字");
Memo1->Lines->Add(L"第 " + sIndex + L" 个字符是汉字");
} |
运行结果:
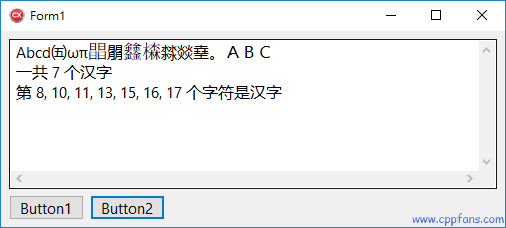
• 可以看到,只有汉字被识别并计数,其他的字母、符号,包括中文标点符号和全角字符都被过滤掉了。
• 字符串里面的汉字是连续的,但是获取到的序号不连续,是因为 “𣊫𨰻𣛧” 这三个汉字是 2 个16 位 char16_t 字符的代理对,第 9、12、14 个字符是后尾代理,他们是不完整的字符,需要和前面的前导代理合在一起,所以没有处理。通过运行结果看到,这样处理的结果是正确的。
例3:获取字符串里面的汉字所在的 CJK 分组
void __fastcall TForm1::Button3Click(TObject *Sender)
{
UnicodeString sText = L"Abcd㈤ωπ𣊫朤𨰻𣛧㵘燚㙓。😏ABC𪢸𫝺𬍛";
Memo1->Lines->Add(sText);
for(int i=1; i<=sText.Length(); i++)
{
int cc = GetCjkCategory(sText, i);
if(cc>=0) // 字符串 sText 里面的第 i 个字符是汉字,CJK 分组为 cc
{
UnicodeString sInfo = sText.SubString(i,cc<2?1:2);
sInfo.cat_sprintf(cc?L":CKJ汉字扩展%c组":L":基本CJK汉字", cc+'A'-1);
Memo1->Lines->Add(sInfo);
}
}
} |
运行结果:
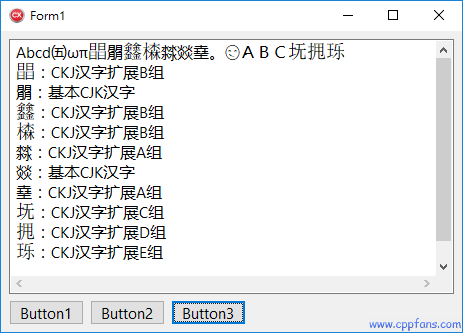
编码转换:UTF-8,UTF-16,UTF-32,ANSI,GBK/GB2312,BIG5,……
更多编码转换的内容,请参考 “字符编码之间转换”。
| UTF-8 的 char * 转为 UnicodeString |
// 假定 char *p 里面是 UTF-8 编码的字符串
UnicodeString u = UTF8String(p);
或者分为两步
UTF8String s = p;
UnicodeString u = s; |
更多编码转换的内容,请参考 “字符编码之间转换”。
UnicodeString 和 std::string, std::wstring 之间的转换,让 std::string 支持 UTF-8 或其他编码
• UnicodeString 和 std::string 之间转换,需要经过 AnsiString, UTF8String, 或 AnsiStringT<CP> 进行中转,
• UnicodeString 和 std::wstring 之间转换,需要经过 c_str() 方法。
例1:C++ Builder 使用第三方的 JsonCpp 开发库
C++ Builder 使用 JsonCpp 支持 UNICODE (UTF-16) / UTF-8
的方法,包括开发库源码、演示程序。
例2:UnicodeString 转为各种编码的 std::string
UnicodeString u = L"Victor, 你好!";
std::string s1 = AnsiString(u).c_str(); // UnicodeString 转为 ANSI 编码的 std::string
std::string s2 = UTF8String(u).c_str(); // UnicodeString 转为 UTF-8 编码的 std::string
std::string s3 = AnsiStringT<950>(u).c_str(); // UnicodeString 转为 BIG5 编码的 std::string
std::string s4 = AnsiStringT<936>(u).c_str(); // UnicodeString 转为 GBK 编码的 std::string |
例3:各种编码的 std::string 转为 UnicodeString
std::string s; // 可以是各种编码的字符串;
UnicodeString u1 = AnsiString(s.c_str()); // 把 ANSI 编码的 std::string 转为 UnicodeString
UnicodeString u2 = UTF8String(s.c_str()); // 把 UTF-8 编码的 std::string 转为 UnicodeString
UnicodeString u3 = AnsiStringT<950>(s.c_str()); // 把 BIG5 编码的 std::string 转为 UnicodeString
UnicodeString u4 = AnsiStringT<936>(s.c_str()); // 把 GBK 编码的 std::string 转为 UnicodeString |
例4:UnicodeString 和 std::wstring 之间转换
UnicodeString u;
std::wstring w;
w = u.c_str(); // UnicodeString 和 std::wstring 之间转换,需要经过 c_str() 方法。
u = w.c_str(); // UnicodeString 和 std::wstring 之间转换,需要经过 c_str() 方法。 |
例5:std::wstring 和 std::string 之间的转换
std::wstring w = L"Victor, 你好!";
std::string s1 = AnsiString(w.c_str()).c_str(); // std::wstring 转为 ANSI 编码的 std::string
std::string s2 = UTF8String(w.c_str()).c_str(); // std::wstring 转为 UTF-8 编码的 std::string
std::string s3 = AnsiStringT<950>(w.c_str()).c_str(); // std::wstring 转为 BIG5 编码的 std::string
std::string s4 = AnsiStringT<936>(w.c_str()).c_str(); // std::wstring 转为 GBK 编码的 std::string
std::string s; // 各种编码的 std::string
std::wstring w1 = UnicodeString(AnsiString(s.c_str())).c_str(); // 把 ANSI 编码的 std::string 转为 std::wstring
std::wstring w2 = UnicodeString(UTF8String(s.c_str())).c_str(); // 把 UTF-8 编码的 std::string 转为 std::wstring
std::wstring w3 = UnicodeString(AnsiStringT<950>(s.c_str())).c_str(); // 把 BIG5 编码的 std::string 转为 std::wstring
std::wstring w4 = UnicodeString(AnsiStringT<936>(s.c_str())).c_str(); // 把 GBK 编码的 std::string 转为 std::wstring |
大小写转换
• UnicodeString 的 UpperCase 和 LowerCase 方法;
• C++ Builder 函数 Sysutils::UpperCase 和 Sysutils::LowerCase;
• C++ Builder 函数 Sysutils::AnsiUpperCase 和 Sysutils::AnsiLowerCase;
• Windows API 函数 CharUpper, CharLower, CharUpperBuff 和 CharLowerBuff;
• Windows API 函数 LCMapString。
| 函数 |
说明 |
| UnicodeString::UpperCase |
字符串转为大写,依照每个 UNICODE 字符本身的属性,请参考 “字符类型 GetUnicodeCategory” |
| UnicodeString::LowerCase |
字符串转为小写,依照每个 UNICODE 字符本身的属性,请参考 “字符类型 GetUnicodeCategory” |
| Sysutils::UpperCase |
把字符串中的英文小写字母 a ~ z 转为英文大写字母 A ~ Z, 其他小写字母不处理 |
| Sysutils::LowerCase |
把字符串中的英文大写字母 A ~ Z 转为英文小写字母 a ~ z, 其他大写字母不处理 |
| Sysutils::AnsiUpperCase |
字符串转为大写,依照每个 UNICODE 字符本身的属性,请参考 “字符类型 GetUnicodeCategory” |
| Sysutils::AnsiLowerCase |
字符串转为小写,依照每个 UNICODE 字符本身的属性,请参考 “字符类型 GetUnicodeCategory” |
| CharUpper |
字符串转为大写,依照每个 UNICODE 字符本身的属性,请参考 “字符类型 GetUnicodeCategory” |
| CharLower |
字符串转为小写,依照每个 UNICODE 字符本身的属性,请参考 “字符类型 GetUnicodeCategory” |
| CharUpperBuff |
字符串前面最多 n 个字符转为大写,规则同 CharUpper |
| CharLowerBuff |
字符串前面最多 n 个字符转为小写,规则同 CharLower |
| LCMapString |
按照某个国家或地区的语言 (LCID) 来处理,把字符串转为大写或小写,或做其他字符处理。 |
转小写测试程序:
void __fastcall TForm1::Button3Click(TObject *Sender)
{
UnicodeString s0 = L"ABCabcΣΩΠσπĀÁǍÀōóǒòêÆå";
UnicodeString s1 = s0.LowerCase(); // 转为小写 (UNICODE)
UnicodeString s2 = LowerCase(s0); // 转为小写 (英文)
UnicodeString s3 = AnsiLowerCase(s0); // 转为小写 (UNICODE)
UnicodeString s4 = s0;
s4.Unique(); // 可以通过数据指针修改字符串内容
CharLower(s4.c_str()); // 转为小写 (UNICODE)
UnicodeString s5 = s0;
s5.Unique(); // 可以通过数据指针修改字符串内容
CharLowerBuff(s5.c_str(), s5.Length()); // 转为小写 (UNICODE)
UnicodeString s6;
LCID lcchs = MAKELCID(MAKELANGID(LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED), SORT_CHINESE_PRCP); // 中国大陆简体中文
int iNewLen = LCMapString(lcchs, LCMAP_LOWERCASE, s0.c_str(), s0.Length(), NULL, 0); // 根据地区规则转小写
if(iNewLen>0)
{
s6.SetLength(iNewLen);
s6.Unique(); // 可以通过数据指针修改字符串内容
LCMapString(lcchs, LCMAP_LOWERCASE, s0.c_str(), s0.Length(), s6.c_str(), iNewLen);
}
Memo1->Lines->Add(L"s0 = " + s0); // s0 原始字符串
Memo1->Lines->Add(L"s1 = " + s1); // s0.LowerCase()
Memo1->Lines->Add(L"s2 = " + s2); // LowerCase()
Memo1->Lines->Add(L"s3 = " + s3); // AnsiLowerCase()
Memo1->Lines->Add(L"s4 = " + s4); // CharLower()
Memo1->Lines->Add(L"s5 = " + s5); // CharLowerBuff()
Memo1->Lines->Add(L"s6 = " + s6); // LCMapString()
} |
运行结果:
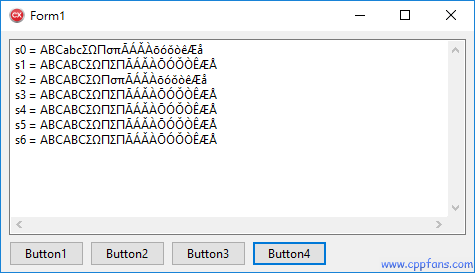
• 只有 LowerCase(s0) 这个方法只处理了英文字母,
没有处理其他字母,比如没有把 ΩΠ 转为 ωπ
• 其他方法转换的结果都一样,所有的大写字母都转为了小写。
• 根据 MSDN 里面的说明,土耳其和阿塞拜疆等国家或地区必须用 LCMapString,他们的字母大小写规则和别的地方不一样。 |  |
转大写测试程序:
void __fastcall TForm1::Button4Click(TObject *Sender)
{
UnicodeString s0 = L"ABCabcΣΩΠσπĀÁǍÀōóǒòêÆå";
UnicodeString s1 = s0.UpperCase(); // 转为大写 (UNICODE)
UnicodeString s2 = UpperCase(s0); // 转为大写 (英文)
UnicodeString s3 = AnsiUpperCase(s0); // 转为大写 (UNICODE)
UnicodeString s4 = s0;
s4.Unique(); // 可以通过数据指针修改字符串内容
CharUpper(s4.c_str()); // 转为大写 (UNICODE)
UnicodeString s5 = s0;
s5.Unique(); // 可以通过数据指针修改字符串内容
CharUpperBuff(s5.c_str(), s5.Length()); // 转为大写 (UNICODE)
UnicodeString s6;
LCID lcchs = MAKELCID(MAKELANGID(LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED), SORT_CHINESE_PRCP); // 中国大陆简体中文
int iNewLen = LCMapString(lcchs, LCMAP_UPPERCASE, s0.c_str(), s0.Length(), NULL, 0); // 根据地区规则转大写
if(iNewLen>0)
{
s6.SetLength(iNewLen);
s6.Unique(); // 可以通过数据指针修改字符串内容
LCMapString(lcchs, LCMAP_UPPERCASE, s0.c_str(), s0.Length(), s6.c_str(), iNewLen);
}
Memo1->Lines->Add(L"s0 = " + s0); // s0 原始字符串
Memo1->Lines->Add(L"s1 = " + s1); // s0.UpperCase()
Memo1->Lines->Add(L"s2 = " + s2); // UpperCase()
Memo1->Lines->Add(L"s3 = " + s3); // AnsiUpperCase()
Memo1->Lines->Add(L"s4 = " + s4); // CharUpper()
Memo1->Lines->Add(L"s5 = " + s5); // CharUpperBuff()
Memo1->Lines->Add(L"s6 = " + s6); // LCMapString()
} |
运行结果:
• 只有 UpperCase(s0) 这个方法只处理了英文字母,
没有处理其他字母,比如没有把 σπê 转为 ΣΠÊ
• 其他方法转换的结果都一样,所有的小写字母都转为了大写。
• 根据 MSDN 里面的说明,土耳其和阿塞拜疆等国家或地区必须用 LCMapString,他们的字母大小写规则和别的地方不一样。 |
 |
分割字符串,利用字符串里面包含的字符或字符串拆分字符串
使用 TStringList 可以分割字符串
例1:使用 Delimiter 和 DelimitedText 进行分割,分割符为单个字符
void __fastcall TForm1::Button5Click(TObject *Sender)
{
UnicodeString s = L"abc,def,ghijk,lmn";
std::auto_ptr<TStringList>sl(new TStringList);
sl->Delimiter = L','; // 使用字符 ',' 分割
sl->StrictDelimiter = true; // 严格使用这个分割符
sl->DelimitedText = s; // 分割字符串 s
for(int i=0; i<sl->Count; i++) // 分割为 sl->Count 个部分
{
Memo1->Lines->Add(sl->Strings[i]); // 输出第 i 个部分到 Memo1
}
}
|
运行结果:
例2:使用 LineBreak 和 Text 进行分割,分割符为字符串
void __fastcall TForm1::Button6Click(TObject *Sender)
{
UnicodeString s = L"汉语+-English+-Português+-Español+-日本語+-한국어";
std::auto_ptr<TStringList>sl(new TStringList);
sl->LineBreak = L"+-"; // 使用字符串 L"+-" 分割
sl->Text = s; // 分割字符串 s
for(int i=0; i<sl->Count; i++) // 分割为 sl->Count 个部分
{
Memo1->Lines->Add(sl->Strings[i]); // 输出第 i 个部分到 Memo1
}
}
|
运行结果:
汉语
English
Português
Español
日本語
한국어 |
字符串相加,几个字符串连接在一起
UnicodeString 类型的字符串之间可以用 + 号相加,他们会连接到一起,
UnicodeString 类型的字符串和字符串常数之间也可以用 + 号相加,他们会连到一起,
要注意,两个字符串常数或字符指针之间不能用 + 号相加,如果必须把他们加在一起,需要转为 UnicodeString 再相加。
UnicodeString s1 = L"abc";
UnicodeString s2 = L"defg";
UnicodeString s3 = L"hijk";
UnicodeString t1 = L"xyz" + s1 + L"," + s2 + s3;
UnicodeString t2 = s1 + L"pqr" + s2 + L"," + s3;
|
wchar_t *p1 = L"d";
wchar_t *p2 = L"e";
wchar_t *p3 = L"f";
UnicodeString s1 = L"y = " + p1 + L"," + p2 + p3;
// 错误:不能把指针加在一起
UnicodeString s2 = UnicodeString(L"y = ") + p1 + L"," + p2 + p3;
// 正确:最先执行的是 UnicodeString 的构造函数,
// 然后把构造出来的临时的对象和 p1 相加,用的是 UnicodeString::operator + ()
// 得出的结果,临时 UnicodeString 对象,再和 L"," 使用 UnicodeString::operator + () 相加
// 同样,之后的都是使用 UnicodeString::operator + () 相加
UnicodeString s3 = L"y = " + UnicodeString(p1) + L"," + p2 + p3;
// 正确:最先执行的是 UnicodeString 的构造函数,
// 然后把 L"y = " 和构造出来的临时的对象相加,
// 这一步使用的是全局的 UnicodeString operator +(const wchar_t *, const UnicodeString &rhs);
// 得出的结果,临时 UnicodeString 对象,再和 L"," 使用 UnicodeString::operator + () 相加
// 同样,之后的都是使用 UnicodeString::operator + () 相加
UnicodeString s4 = L"y = " + p1 + UnicodeString(L",") + p2 + p3;
// 错误:最先执行的是两个指针相加 (L"y = " 和 p1)
|
UnicodeString 可以和 AnsiString、UTF8String、AnsiStringT 进行相加,会连接到一起
要注意,他们之间可以自动编码转换,但是在编码转换的过程中可能会丢失数据
如果不确定可能会发生的结果,都转为 UnicodeString 之后再相加会尽可能的减少数据丢失。
void __fastcall TForm1::Button1Click(TObject *Sender)
{
UnicodeString s1 = L"©第一个🍎";
AnsiString s2 = L"©第二个🍎";
UTF8String s3 = L"©第三个🍎";
AnsiStringT<936> s4 = L"©第四个🍎";
Memo1->Lines->Add(s1 + L", " + s2 + L", " + s3 + L", " + s4);
Memo1->Lines->Add(s2 + L", " + s3 + L", " + s4 + L", " + s1);
Memo1->Lines->Add(L"" + s2 + L", " + s3 + L", " + s4 + L", " + s1);
} |
运行结果:
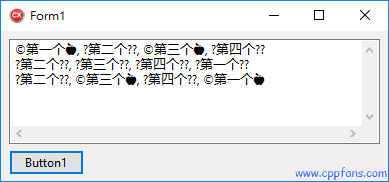
由于 + 操作符会把字符串转为 + 号前面的类型,相加的结果也是 + 号前面的类型,
所以,连起来几个 + 号相加的字符串,都转为了第一个被加的字符串的类型了,
第一行的结果:s1 和 s3 没有丢失数据,因为第一个被加的字符串 s1 是 UnicodeString,都转为 UnicodeString 相加,
第二行的结果:s1 和 s3 都丢失数据了,因为第一个被加的字符串 s2 是 AnsiString,都转为 AnsiString 相加,
第三行的结果:s1 和 s3 没有丢失数据,因为第一个被加的字符串 L"" 是 UTF-16 编码字符串常数,都转为 UnicodeString 相加。
截取字符串的一部分,把字符串前面或/和后面的空格删掉,把字符串当中的一部分删掉
用 UnicodeString 的 SubString 方法截取字符串的一部分:
UnicodeString s = L"abcd甲乙丙丁";
UnicodeString t = s.SubString(3,5); |
截取字符串 s 的第 3 个字符开始的 5 个字符长度,得到的字符串为:
删除字符串前面或后面的空格,用 UnicodeString 的 TrimLeft, TrimRight 和 Trim 方法:
UnicodeString s = L" 甲乙 丙丁 ";
UnicodeString u = s.TrimLeft(); // 删除前面的空格:L"甲乙 丙丁 "
UnicodeString v = s.TrimRight(); // 删除后面的空格:L" 甲乙 丙丁"
UnicodeString w = s.Trim(); // 删除两边的空格:L"甲乙 丙丁" |
删除字符串中间的一部分,用 UnicodeString 的 Delete 方法:
UnicodeString s = L"甲乙丙丁戊己更辛";
UnicodeString t = s.Delete(3,4); // L"甲乙更辛" |
删除从第 3 个字符 '丙' 开始的 4 个字符:"丙丁戊己"
结果:剩下的 "甲乙更辛"
字符串中间加入字符串,用 UnicodeString 的 Insert 方法:
UnicodeString s = L"甲乙丙丁戊己更辛";
UnicodeString t = s.Insert(L") ",7).Insert(L" (",3); |
先在字符串 s 的第 7 个字符位置插入字符串 L") ",然后在第 3 个字符的位置插入字符串 L" ("
结果为:
把字符串里面的某个内容替换为另一个内容
使用 StringReplace 函数,可以把字符串里面的某个内容替换为另一个内容。
字符串和整数、浮点数、日期时间之间的转换
字符串和整数之间的转换,进位制转换
C++ Builder 函数,整数和字符串之间的转换:
| 函数 |
说明 |
| IntToStr |
UnicodeString __fastcall IntToStr(int Value);
整数 Value 转为 10 进制字符串 |
| IntToHex |
UnicodeString __fastcall IntToHex(int Value, int Digits);
整数 Value 转为 16 进制字符串,最少输出 Digits 位,不足 Digits 位前面补 0 |
| StrToInt |
int __fastcall StrToInt(const System::UnicodeString S);
字符串转为整数,如果转换失败,会抛出 EConvertError 异常。
字符串以 0x 开头认为是 16 进制,否则认为是 10 进制。 |
| StrToInt64 |
__int64 __fastcall StrToInt64(const System::UnicodeString S);
字符串转为 64 位整数,如果转换失败,会抛出 EConvertError 异常。
字符串以 0x 开头认为是 16 进制,否则认为是 10 进制。 |
| StrToUInt64 |
unsigned __int64 __fastcall StrToUInt64(const System::UnicodeString S);
字符串转为无符号 64 位整数,如果转换失败,会抛出 EConvertError 异常。
字符串以 0x 开头认为是 16 进制,否则认为是 10 进制。 |
| StrToIntDef |
int __fastcall StrToIntDef(const System::UnicodeString S, int Default);
字符串转为整数,如果转换失败,返回默认值 Default,不会抛出异常。
字符串以 0x 开头认为是 16 进制,否则认为是 10 进制。 |
| StrToInt64Def |
__int64 __fastcall StrToInt64Def(const System::UnicodeString S, const __int64 Default);
字符串转为 64 位整数,如果转换失败,返回默认值 Default,不会抛出异常。
字符串以 0x 开头认为是 16 进制,否则认为是 10 进制。 |
| StrToUInt64Def |
unsigned __int64 __fastcall StrToUInt64Def(const System::UnicodeString S, const unsigned __int64 Default);
字符串转为无符号 64 位整数,如果转换失败,返回默认值 Default,不会抛出异常。
字符串以 0x 开头认为是 16 进制,否则认为是 10 进制。 |
C 语言库函数,整数转各种进位制的字符串:
这些函数的参数:
第 1 个参数为整数值,int, long, unsigned long, __int64, unsigned __int64 等;
第 2 个参数为生成的字符串,char * 或 wchar_t * 类型,必须有足够空间容纳生成的字符串,包括字符串结束符 '\0';
第 3 个参数为进位制,2 ~ 36 的整数值,为二进制 ~ 三十六进制;
返回值:第二个参数,即生成的字符串,char * 或 wchar_t * 类型。
C 语言库函数,各种进位制的字符串转为整数:
这些函数的参数:
第 1 个参数为需要转为整数的字符串,char * 或 wchar_t *;
第 2 个参数为指向转换错误的字符的指针的指针,char ** 或 wchar_t **;如果转换成功,指向字符串结束符,如果失败,指向出错字符;
第 3 个参数为进位制,2 ~ 36 为二进制到三十六进制,0 为根据字符串前面的字符识别,0x 开头认为是 16 进制,0 开头认为是 8 进制,1 ~ 9 开头认为是 10 进制。
返回值为转换之后的整数。
例:
int i1 = 1234, i2 = 123456;
UnicodeString s1 = IntToStr(i1); // 1234
UnicodeString s2 = IntToStr(i2); // 123456
UnicodeString s3 = IntToHex(i1, 4); // 04D2
UnicodeString s4 = IntToHex(i2, 4); // 1E240 |
例:把一个无符号长整型数值转为 10, 2, 8, 16 进制字符串:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
unsigned long i = 2882343476ul;
wchar_t sBuf[33]; // 最长情况:转成 2 进制是 32 位的
Memo1->Lines->Add(_ultow(i, sBuf, 10)); // 转为 10 进制
Memo1->Lines->Add(_ultow(i, sBuf, 2)); // 转为 2 进制
Memo1->Lines->Add(_ultow(i, sBuf, 8)); // 转为 8 进制
Memo1->Lines->Add(_ultow(i, sBuf, 16)); // 转为 16 进制
}
|
运行结果:
2882343476
10101011110011010001001000110100
25363211064
abcd1234 |
例:利用 C++ Builder 自带的函数进行 16 进制转 10 进制。把编辑框 Edit1 里面的 16 进制数转为 10 进制,输出到编辑框 Edit2 里面
void __fastcall TForm1::Button1Click(TObject *Sender)
{
try
{
int i = StrToInt(L"0x" + Edit1->Text);
Edit2->Text = IntToStr(i);
}
catch(Exception &e)
{
ShowMessage(L"转换失败,错误信息:\r\n" + e.Message);
}
}
|
运行结果:
如果 Edit1 里面输入 xyz,点击 Button1 按钮,会弹出错误提示:转换失败,错误信息:0xxyz is not a valid integer value.
如果 Edit1 里面输入 abcd,点击 Button1 按钮,Edit2 里面会输出 43981,即 16 进制的 abcd 转为了 10 进制的 43981
例:把二进制数字符串转为 10 进制数
void __fastcall TForm1::Button1Click(TObject *Sender)
{
UnicodeString s = Edit1->Text;
wchar_t *ep;
unsigned long i = wcstoul(s.c_str(), &ep, 2);
if(*ep)
ShowMessage(L"从这里开始无法转换:" + UnicodeString(ep));
else
Edit2->Text = i;
}
|
运行结果:
如果 Edit1 里面输入 101010,点击按钮 Button1,Edit2 里面输出 42,即二进制数据 101010 转为 10 进制等于 42,
如果
Edit1 里面输入 101023,点击按钮 Button1,会弹出错误提示:从这里开始无法转换:23
字符串和枚举型之间的转换
s = EnumToStr(t); 把枚举型变量 t 的值转为枚举值对应的字符串 s。
t = StrToEnum<EnumType>(s); 把字符串 s 转为枚举类型 EnumType 类型的值 t。
例1:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
Memo1->Lines->Add(EnumToStr(this->BorderStyle));
Memo1->Lines->Add(EnumToStr(this->Position ));
Memo1->Lines->Add(EnumToStr(this->WindowState));
} |
获取到这些属性的枚举值对应的字符串 bsSizeable, poDesigned, wsNormal
例2:
enum TMyEnum { First, Second, Third };
void __fastcall TForm1::Button2Click(TObject *Sender)
{
TMyEnum e = Second;
Memo1->Lines->Add(EnumToStr(e));
} |
获取到枚举值 e 当前值对应的字符串 Second
例3:
把 L"wsMaximized" 和 L"wsNormal" 转成对应的 TWindowState 枚举值,赋值给 this->WindowState 让窗口最大化和还原。
void __fastcall TForm1::Button3Click(TObject *Sender)
{
UnicodeString s = L"wsMaximized";
this->WindowState = StrToEnum<TWindowState>(s);
}
//---------------------------------------------------------------------------
void __fastcall TForm1::Button4Click(TObject *Sender)
{
UnicodeString s = L"wsNormal";
this->WindowState = StrToEnum<TWindowState>(s);
}
//--------------------------------------------------------------------------- |
字符串和浮点数之间的转换,小数点位数、千分位分割、科学计数法
使用 C++ Builder 函数 FormatFloat 和 FloatToStrF
double x = 12345.678;
Edit1->Text = FormatFloat(L"0.00" , x);
Edit2->Text = FormatFloat(L"#,##0.00", x);
Edit3->Text = FloatToStrF(x, ffExponent, 5, 3); |
运行结果:
Edit1 输出 12345.68 因为 L"0.00" 表示小数点后面保留 2 位,
Edit2 输出 12,345.68 因为 L"#,##0.00" 表示千分位分割,小数点后面保留 2 位
Edit3 输出 1.2346E+004 因为输出需要的是 5 位有效数字,即 1.2346 和 3 位指数,即 004,数字 1.2346E+004 相当于 1.2346×10⁴。
例:字符串转浮点数,由于 StrToFloat 不识别千分位符号,所以需要把 s2 里面的 “,” 全部去掉再转换才能成功
UnicodeString s1 = L"987.654";
UnicodeString s2 = L"1,234,567.89";
double x = StrToFloat(s1);
double y = StrToFloat(StringReplace(s2,L",",L"",TReplaceFlags()<<rfReplaceAll)); |
运行结果:
x = 987.654
y = 1234567.89 |
字符串和日期时间之间的转换,日期时间的格式
日期转字符串:
格式化输出到字符串
例:int i = 5; double f = 1.356; 以下 3 条代码都能得到 L"i=5, f=1.36" 的字符串 s
| s.sprintf(L"i=%d, f=%.2f", i, f); |
| s.printf(L"i=%d, f=%.2f", i, f); |
| s = UnicodeString::Format(L"i=%d, f=%.2f", ARRAYOFCONST((i,f))); |
例:在保留原来字符串内容的基础上,字符串后面添加格式化输出的结果:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
UnicodeString s;
int i = 5; double f = 1.356;
s.cat_sprintf(L"i = %d\r\n" , i);
s.cat_sprintf(L"f = %.2f\r\n", f);
Memo1->Text = s;
} |
运行结果:
例:使用 s.vprintf 做的 ShowMsg 函数,格式输出到 Memo1 多行编辑框
void __stdcall TForm1::ShowMsg(const wchar_t *Msg,...)
{
try
{
Memo1->Lines->BeginUpdate();
UnicodeString s;
va_list vl;
va_start(vl, Msg);
s.vprintf(Msg, vl);
va_end(vl);
Memo1->SelStart = Memo1->Text.Length();
Memo1->SelLength = 0;
Memo1->SelText = s;
while(Memo1->Lines->Count>100)
Memo1->Lines->Delete(0);
}
__finally
{
Memo1->Lines->EndUpdate();
}
}
//---------------------------------------------------------------------------
void __fastcall TForm1::Button6Click(TObject *Sender)
{
int i = 5; double f = 1.356;
ShowMsg(L"计算结果是:\r\n");
ShowMsg(L"i=%d, f=%.2f\r\n", i, f);
}
//--------------------------------------------------------------------------- |
相关链接:
UnicodeString 成员
UnicodeString 赋值、数据指针、引用计数的测试
获取字符串或字符的 ANSI 代码页列表
|