ANSI / SBCS / DBCS / MBCS / ASCII / EUC / EUC-CN / GB2312 / GBK / GB18030 / BIG5
ANSI: American National Standards Institute 美国国家标准学会,由这个标准学会制订的一种编码规则。
• 采用多字节系统 (MBCS) 的变长编码,每个字符可以是单个字节、双字节,也可以是多字节的;
• 兼容单字节字符集 (SBCS) 和双字节字符集 (DBCS);
• 兼容 EUC/EUC-CN 双字节编码。由于兼容了这个编码,那么 ANSI 的双字节编码也是大端存储 (Big Endian) 的了;
• 不同的国家和地区可以使用不同的编码规则,这些编码对应到这些国家和地区的代码页 (Code Page) 上。
SBCS: Single Byte Character Set 单字节字符集。
• 每个字符都是 1 个字节的编码,ASCII 是 1 个字节的编码,很多欧洲语言 1 个字节的编码也足够了。
• ANSI 兼容了 SBCS,每个国家和地区的编码可能都不同,对应到这些国家和地区的代码页 (Code Page) 上。
DBCS: Double-Byte Character Set 双字节字符集。
• 每个字符是 1 个或 2 个字节的编码,规则请参考后面的 “字节类型” 里面的描述。
• ANSI 兼容了 DBCS,每个国家和地区的编码可能都不同,对应到这些国家和地区的代码页 (Code Page) 上。
MBCS: Multi-Byte Chactacter Set (System) 多字节字符集。
• 每个字符采用 1 个或多个字节的编码,规则请参考后面的 “字节类型” 里面的描述。
• ANSI 兼容了 MBCS,每个国家和地区的编码可能都不同,对应到这些国家和地区的代码页 (Code Page) 上。
Byte Type:字节类型,DBCS/MBCS 双字节/多字节系统,每个字符的字节数不同,为了区分哪些字节是组合在一起的,哪些是单个字节的字符
首先看 DBCS 双字节字符集的编码规则:
• Single Byte: 单字节字符,编码范围 0x00 ~ 0x7F;
• Lead Byte: 双字节字符的第一个字节,范围 0x80 ~ 0xFF,遇到这样的字符,认后面还有一个和它组合在一起的字符;
• Trail Byte: 双字节字符的第二个字符,范围 0x01 ~ 0xFF,因为只要找了 Lead Byte,跟在它后面的就是 Trail Byte,所以 Trail Byte 可以使用任何编码值不等于 0 的字符。
然后看 MBCS 多字节字符集的编码规则:
• 在 DBCS 的基础上,兼容 DBCS,是 DBCS 的升级版本;
• 超出 DBCS 编码的范围了,需要用 4 个字节的编码的时候,用 2 个标准的 DBCS 的双字节字符表示 4 个字节的字符。所以,4 个字节的字符的字节类型依次为 Lead Byte, Trail Byte, Lead Byte, Trail Byte。
• 根据什么判断 MBCS 字符到底是 2 字节还 4 字节呢?只有看编码范围了。
比如 GB18030 编码,就是 MBCS 多字节系统,GB18030 利用 Trail Byte 的值区分双字节字符和四字节字符:
GB18030 规定 Lead Byte 的范围是 0x81 ~ 0xFE,Trail Byte 的范围是 0×30 ~ 0×39, 0×40 ~ 0×7E, 0×80 ~ 0×FE。
• Trail Byte 范围 0×40 ~ 0×7E 或 0×80 ~ 0×FE,这样的字符,是双字节字符。
• Trail Byte 范围 0×30 ~ 0×39,那么这个字符就是 4 个字节的字符。
例如:0x81, 0x40 是双字节的,0x81, 0x30 就是 4 个字节的,前面或后面还有一个双字节字符和它组合在一起。
请参考 GB18030 编码测试程序 查看和进一步了解 Byte Type 和 MBCS / GB18030 的编码规则。
ASCII: American Standard Code for Information Interchange,美国信息交换标准代码。
• ASCII 读音为 /ˈæski/ 或 ass-kee,
因为后面的 II 是 Information Interchange 的缩写,不是罗马数字 “Ⅱ”,所以读为 “阿斯克”,而不能读作 “阿斯克二”。
• 只有 7 位的二进制编码,范围从 0 ~ 127,一共 128 个字符,包含英文字母、数字、标点符号和一些控制符。
• 所谓的 “两个 ASCII 表示一个汉字” 是属于 ANSI 编码,这里的 ASCII 是不能表示汉字的。
EASCII: Extended ASCII,延伸美国标准信息交换码
• 在 ASCII 的基础上,从 7 位二进制编码扩充到 8 位二进制码,范围 0 ~ 255,一共 256 个字符。
• 对应于代码页 Code Page 437,所以又称为 CP 437,OEM 437,DOS-USA 或 MS-DOS Latin US。
• 所谓的 “两个 ASCII 表示一个汉字” 是属于 ANSI 编码,这里的 ASCII 是不能表示汉字的,汉字的代码页是 936 或 950,而不是 437。
GB2312:
中国大陆和新加坡使用的一种早期的汉字编码,标准编号为 GB2312-1980,是中国国家标准总局 1980 年发布的信息交换用汉字编码字符集,收录了 6763 个汉字,682 个全角字符。其中一级汉字 3755 个,二级汉字 3008 个,全角字符包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等。
区位码:GB2312 采用分区的方式编码:
• 01~09 区为符号和特殊字符,
• 10~15 区未使用,
• 16~55
区为一级汉字,有 3755 个最常用的汉字,按照汉语拼音的顺序排列,
• 56~87 区为二级汉字,有 3008 个次常用的汉字,按照部首及笔画顺序排列,
• 88~94 区未使用,
这些汉字或符号的编码,第几区的数值为 “区码”,这个字是这个区的第几个字,为 “位码”,例如 “啊” 的 GB2312 的第一个汉字,是第 16 区的第 01 个字,它的区位码就是 1601。
EUC 编码:这是早期的双字节编码方式,在 ANSI 之前,大家都遵照这个标准
EUC (Extended Unix Code) 是一个使用 8 位编码来表示字符的方法。
EUC 规定单字节编码范围 0x00 ~ 0x7F,双字节编码采用两个 0x80 ~ 0xFF 的字节,对应于区位码上,
“区码” 加上一个数值,范围调整在 0x80 ~ 0xFF 之内,称为 “区字节”,是编码的高位字节,
“位码” 加上一个数值,范围调整在 0x80 ~ 0xFF 之内,称为 “位字节”,是编码的低位字节,
由此可见,EUC 是一个大端存储 (Big Endian) 的编码方式。
EUC-CN 是中国的 EUC 编码,即 GB2312 编码。
区字节 = 区码 + 0xA0,为编码的高位字节,EUC 是 Big Endian 的,区字节储存在电脑里面要放在前面,
位字节 = 位码 + 0xA0,为编码的低位字节,EUC 是 Big Endian 的,位字节储存在电脑里面要放在后面。
国标码,汉字机内码 (汉字内码)
• 机内码:EUC-CN 的区字节和位字节组合在一起,就是 GB2312 的机内码 (汉字内码),区字节为高位字节,位字节为低位字节。
• 国标码:机内码的高位字节和低位字节,都把最高位清零,低 7 位不变,即 “国标码 = 机内码 - 0x8080”。
最终存储在电脑里存储器面的编码值:以上让人头晕眼花的描述中的 GB2312,或者说 EUC-CN 的所有的 “码” 中,只有汉字机内码是储存在电脑里面的格式,是他们的最终编码,通常都是用十六进制表示的。
GB2312 编码与 ANSI 的对应:
• 对应于代码页 Code Page 20936 (大陆及新加坡的代码页为 CP 936,即 GBK 编码,很少有人使用 CP 20936)。
• Lead Byte = 区字节,由于 ANSI 要兼容 EUC,那么就要采用大端存储 (Big Endian),把高位字节放在前面;
• Trail Byte = 位字节,由于 ANSI 要兼容 EUC,那么就要采用大端存储 (Big Endian),把低位字节放在后面。
例如,依然是采用字符编码的例子当中的一个 ANSI 编码字符的例子:
这个是 ANSI 版本的编译器,例如 C++ Builder 编译器在 Windows 环境下 ANSI 版本的项目编译运行的结果。
如果你的编译器不支持,请看下一个例子————GB2312 字符串的例子。
#include <stdio.h>
int _tmain(int argc, _TCHAR* argv[])
{
unsigned short c = '我' ; // 内码 = 字符本身的值 (CP936 代码页 ANSI 编码的值)
unsigned short gb = c & 0x7F7F ; // 国标码 = 内码两个字节高位都清零
unsigned char qz = c >> 8 ; // 区字节 = 内码高位字节
unsigned char wz = c & 0x00FF ; // 位字节 = 内码低位字节
unsigned char qm = qz - 0xA0 ; // 区码 = 区字节 - 0xA0
unsigned char wm = wz - 0xA0 ; // 位码 = 位字节 - 0xA0
unsigned short qw = qm*100 + wm; // 区位码是十进制的,要用十进制计算
unsigned char lb = qz ; // Lead Byte = 区字节,因为是大端存储 (Big Endian)
unsigned char tb = wz ; // Trail Byte = 位字节,因为是大端存储 (Big Endian)
printf("'我' 的机内码 = %04X\n" , c );
printf("'我' 的国标码 = %04X\n" , gb );
printf("'我' 的区字节 = 0x%02X\n" , qz );
printf("'我' 的位字节 = 0x%02X\n" , wz );
printf("'我' 的区码 = %02d\n" , qm );
printf("'我' 的位码 = %02d\n" , wm );
printf("'我' 的区位码 = %04d\n" , qw );
printf("'我' 的 Lead Byte = 0x%02X\n" , lb );
printf("'我' 的 Trail Byte = 0x%02X\n" , tb );
char s[] = { lb, tb, 0 }; // 储存在字符串前面的是 Lead Byte,后面的是 Trail Byte
printf("由 Lead Byte 和 Trail Byte 合成字符串 = \"%s\"\n", s); // 输出字符串
printf("\n请按回车键退出..."); getchar();
return 0;
} |
运行结果:
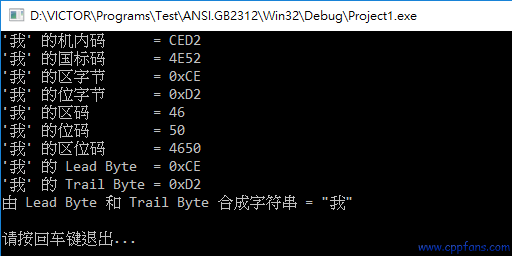
| 汉字 '我' 的 | 值 | 说明 |
| 机内码 |
CED2 |
单个字符,得到 '我' 的字符编码,即汉字机内码 (汉字内码),整数值为 c = 0xCED2 (十进制的 52946)。 |
| 国标码 |
4E52 |
把汉字内码两个字节 0xCE 和 0xD2 的高位清零,得到 0x4E, 0x52,也可以用 0xCED2 - 0x8080 = 0x4E52 |
| 区字节 |
0xCE |
'我' 的区字节为高位字节 0xCE,即 ANSI 的 Lead Byte |
| 位字节 |
0xD2 |
'我' 的位字节为低位字节 0xD2,即 ANSI 的 Trail Byte |
| 区码 |
46 |
'我' 的区码是 46 即区字节 0xCE - 0xA0 = 0x2E (0x2E 等于十进制的 46), |
| 位码 |
50 |
'我' 的位码是 50,即位字节 0xD2 - 0xA0 = 0x32 (0x32 等于十进制的 50), |
| 区位码 |
4650 |
'我' 的区位码是 4650,是根据前面两条,区码和位码合在一起得到的结论。 |
| Lead Byte |
0xCE |
在电脑存储器里面储存的字符串,在前面的是 Lead Byte,由于是大端存储 (Big Endian),是区字节 0xCE |
| Trail Byte |
0xD2 |
在电脑存储器里面储存的字符串,在后面的是 Trail Byte,由于是大端存储 (Big Endian),是位字节 0xD2 |
注:在中国大陆简体中文的电脑里面得到的是 GB2312 编码,在中国港台地区得到的是 BIG5 码,他们的概念相同,但是编码值不同。
再继续写一个例子————GB2312 字符串的例子:
如果你的编译器不支持前面的 ANSI 字符的例子,可以用这个例子。
这个例子是在 C++ Builder 编译器里面 Windows 系统 ANSI 编码版本的项目运行通过的,也可以兼容 DOS/EUC-CN 环境。
#include <stdio.h>
int _tmain(int argc, _TCHAR* argv[])
{
char s[] = "我";
unsigned char lb = s[0] ; // ANSI: 储存在字符串前面的是 Lead Byte
unsigned char tb = s[1] ; // ANSI: 储存在字符串后面的是 Trail Byte
unsigned char qz = lb ; // 区字节 = Lead Byte,因为是大端存储 (Big Endian)
unsigned char wz = tb ; // 位字节 = Trail Byte,因为是大端存储 (Big Endian)
unsigned short nm = (qz<<8)|wz ; // 内码 = 区字节是高位字节,位字节是低位字节
unsigned short gb = nm & 0x7F7F ; // 国标码 = 内码两个字节高位都清零
unsigned char qm = qz - 0xA0 ; // 区码 = 区字节 - 0xA0
unsigned char wm = wz - 0xA0 ; // 位码 = 位字节 - 0xA0
unsigned short qw = qm*100 + wm ; // 区位码是十进制的,要用十进制计算
printf("原始字符串 = \"%s\"\n" , s );
printf("'我' 的 Lead Byte = 0x%02X\n" , lb );
printf("'我' 的 Trail Byte = 0x%02X\n" , tb );
printf("'我' 的区字节 = 0x%02X\n" , qz );
printf("'我' 的位字节 = 0x%02X\n" , wz );
printf("'我' 的机内码 = %04X\n" , nm );
printf("'我' 的国标码 = %04X\n" , gb );
printf("'我' 的区码 = %02d\n" , qm );
printf("'我' 的位码 = %02d\n" , wm );
printf("'我' 的区位码 = %04d\n" , qw );
printf("\n请按回车键退出..."); getchar();
return 0;
} |
运行的结果:

| 汉字 '我' 的 |
值 |
说明 |
| Lead Byte |
0xCE |
在电脑存储器里面储存的字符串,在前面的是 Lead Byte,由于是大端存储 (Big Endian),是区字节 0xCE |
| Trail Byte |
0xD2 |
在电脑存储器里面储存的字符串,在后面的是 Trail Byte,由于是大端存储 (Big Endian),是位字节 0xD2 |
| 区字节 |
0xCE |
'我' 的区字节为高位字节 0xCE,即 ANSI 的 Lead Byte |
| 位字节 |
0xD2 |
'我' 的位字节为低位字节 0xD2,即 ANSI 的 Trail Byte |
| 机内码 |
CED2 |
区字节和位字节合在一起就是机内码,区字节是高位字节,位字节是低位字节。 |
| 国标码 |
4E52 |
把汉字内码两个字节 0xCE 和 0xD2 的高位清零,得到 0x4E, 0x52,也可以用 0xCED2 - 0x8080 = 0x4E52 |
| 区码 |
46 |
'我' 的区码是 46 即区字节 0xCE - 0xA0 = 0x2E (0x2E 等于十进制的 46), |
| 位码 |
50 |
'我' 的位码是 50,即位字节 0xD2 - 0xA0 = 0x32 (0x32 等于十进制的 50), |
| 区位码 |
4650 |
'我' 的区位码是 4650,是根据前面两条,区码和位码合在一起得到的结论。 |
注:在中国大陆简体中文的电脑里面得到的是 GB2312 编码,在中国港台地区得到的是 BIG5 码,他们的概念相同,但是编码值不同。
GBK: 国标扩展码,是中国大陆 1995 年制定的编码标准,这是一个过渡版本的标准,正式版本为 GB13000。
• 在 GB2312 的基础上,扩充了编码范围,和 GB2312 完全兼容:
• 区字节范围:0x81 ~ 0xFE,对应于 ANSI 版本的 Lead Byte,
• 位字节范围:0x40 ~ 0x7E 和 0x80 ~ 0xFE 两段,中间不包含 0x7F 这个值,对应于 ANSI 版本的 Trail Byte。
• 一共 23940 个码位,收录了 21003 个汉字,包括 GB2312 全部汉字、BIG5 编码的所有汉字和新增加的汉字。
• 对应于 ANSI 代码页 Code Page 936,简称 CP 936。
• 和 GB13000 的区别: 同一套文字的两种不同编码,GB13000-1993 采用 UCS2 编码,GB13000-2010 采用 UTF-16 编码,详见 UNICODE 章节。
虽说 GBK 为国家标准的过渡标准,正式标准为 GB13000-1993 和 GB13000-2010,但是到现在为止,大家还在折腾 CP 936 代码页的 GBK 编码的 ANSI 版本的程序呢。
大家都不遵照 GB13000 标准写程序,这个不愿大家,要愿就愿微软公司。GB13000 在 1993 年就制定了,在这个标准之后出版的 Windows 95 是 ANSI 编码的,CP 936 代码页映射在了 GBK 编码上,不支持 UNICODE,也不支持 GB13000。这样的系统一直持续到 Windows 2000 出版之前。
虽说 Windows 2000 开始,操作系统的内核改成了 UTF-16 编码,兼容 GB13000 了,可是微软又把 ANSI 留下来了,CP 936 代码页的 GBK 编码仍然能用,老程序员写程序习惯了就不愿意改了,新程序员学习的老程序员的经验,书和资料也更新的不及时,所以新程序员也不愿意改用新标准。
本文作者 -- Victor Chen 建议大家再创建新的项目采用 UNICODE 编码版本的程序,这样不仅仅是和新的国家标准兼容,而且还实现了国际化。
GB18030: 目前中国大陆最新的 MBCS 字符编码标准。GB18030 是在 GBK 的基础上进行了扩充。
• GB18030-2000,是 2000 年发布的,
• GB18030-2005,是 2005 年发布的,目前正在使用的标准,
• GB18030 的代码页为 CP 54936。
• GB18030-2005 兼容 GBK/GB2312,收录了 70244 个汉字,包含了 GBK、GB2312、GB13000 的汉字和扩充的汉字,还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。
• 2000 年发布的 GB18030-2000 取代了 GBK,并且要求 PC 平台所有的软件都必须强制支持 GB18030,嵌入式平台没有强制要求。
• 编码方式参考 ANSI 的 Byte Type (字节类型),分为单字节字符、双字节字符和四字节字符,即每个字符 1, 2 或 4 个字节。
对于这个编码,本文作者 -- Victor Chen 又有话要说了:
• 对于强制执行,大家常用的软件当中,从来没发现有支持 GB18030 的 ANSI / MBCS 版本的软件,也没发现有任何程序员希望自己的程序支持 GB18030,虽说理论上肯定有这样的软件。现在的 ANSI / MBCS 版本的软件,包括刚刚出版的新版软件,甚至还有不支持 GBK 的,仅仅支持 GB2312。
• UNICODE 版本的软件,按理说就不是 GB18030 这样的 ANSI 系列或 MBCS 系列的编码了,如果程序员没有 “自作聪明” 的自己去玩处理 UNICODE 编码,肯定会支持 GB18030 所有的字符的,因为 UNICODE 已经涵盖了 GB18030 所有的字符。
• 自作聪明的程序员太多了,我遇到了无数多个,包括现实生活中的、论坛里面的、IM 聊天软件里面的,他们自己处理了 UNICODE 编码值,把汉字限制在 U+4E00 ~ U+9FBF 这个基础的 CJK 编码范围,也许是为了偷懒,这太糟糕了,甚至无法涵盖 GBK 的范围,更别说 GB18030 了。
GB18030 编码的字节类型,字符个数和字节数 - 判断字符串里面的字符是双字节字符或是单字节字符,还有四字节字符的判断
 【例:多字节字符集 (MBCS) 的例子 - GB18030 编码的例子】 【例:多字节字符集 (MBCS) 的例子 - GB18030 编码的例子】
GB18030 测试程序:
• 这个测试程序很无聊?其实不然,因为在很久以前国家标准就规定了,要强制执行 GB18030 标准,那么无论如何也要了解一下。
void __fastcall TForm1::Button1Click(TObject *Sender)
{
UnicodeString utf16 = L"𠀾"; // 这是一个 UTF-16 字符串
UTF8String utf8 = utf16; // 转为 UTF-8 字符串: UTF8String
AnsiString ansi = utf16; // 转为 ANSI 字符串: AnsiString
AnsiStringT<936> gbk = utf16; // 转为 GBK 编码的字符串
AnsiStringT<54936> gb18030 = utf16; // 转为 GB18030 编码的字符串
char *pstr = gb18030.c_str(); // pstr 指针指向 GB18030 编码的字符串
Memo1->Lines->Add(String(L"UTF-16 字符串: \"") + utf16 + L"\"");
Memo1->Lines->Add(String(L"UTF-8 字符串: \"") + utf8 + L"\"");
Memo1->Lines->Add(String(L"ANSI 字符串: \"") + ansi + L"\"");
Memo1->Lines->Add(String(L"GBK 字符串: \"") + gbk + L"\"");
Memo1->Lines->Add(String(L"GB18030 字符串: \"") + gb18030 + L"\"");
Memo1->Lines->Add(String(L"指向 GB18030 的 char *: \"") + pstr + L"\"");
UnicodeString s;
s = L"";
for(int i=0; pstr[i]; i++)
{
if(!s.IsEmpty()) s += L", ";
s.cat_sprintf(L"0x%02X", (int)(unsigned char)pstr[i]);
}
Memo1->Lines->Add(L"GB18030 编码: " + s);
s = L"";
for(int i=1; i<=utf8.Length(); i++)
{
if(!s.IsEmpty()) s += L", ";
s.cat_sprintf(L"0x%02X", (int)(unsigned char)utf8[i]);
}
Memo1->Lines->Add(L"UTF-8 编码: " + s);
s = L"";
for(int i=1; i<=utf16.Length(); i++)
{
if(!s.IsEmpty()) s += L", ";
s.cat_sprintf(L"0x%04X", utf16[i]);
}
Memo1->Lines->Add(L"UTF-16 编码: " + s);
UCS4String utf32 = UnicodeStringToUCS4String(utf16);
s = L"";
for(int i=0; utf32[i]; i++)
{
if(!s.IsEmpty()) s += L", ";
s.cat_sprintf(L"0x%X", utf32[i]);
}
Memo1->Lines->Add(L"UTF-32 编码: " + s);
s.sprintf(L"U+%X", utf32[0]);
Memo1->Lines->Add(L"UNICODE 编码: " + s);
} |
运行结果:
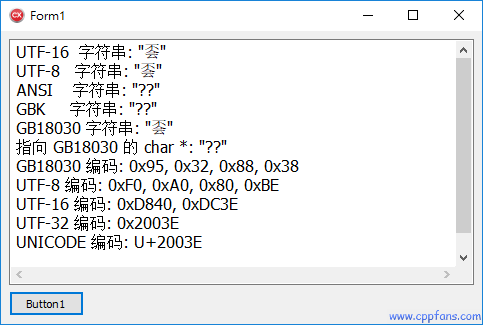
从这个程序的运行结果来看:
• 常用的 UnicodeString、UTF8String 显示正常,
• 常用的 AnsiString 和 char * 显示失败,变成了俩问号 "??",因为他们是系统默认的代码页 CP 936,对应的是 GBK 编码,
• AnsiStringT<936> 指定了代码页为 936,那么就是 GBK 编码了,“𠀾” 这个字不在 GBK 编码之内,所以无法转换成功和显示,
• AnsiStringT<54936> 指定了代码页为 54936,那么就是 GB18030 编码了,转换编码成功,并且正常显示出来了,
• char *pstr 指向的是 GB18030 编码的字符串,但是无法直接显示出来,因为系统认为 char * 是默认的 CP 936 代码页 GBK 编码,
• 通过 pstr 显示出来的 GB18030 的编码值是正确的,0x95, 0x32, 0x88, 0x38,通过 Byte Type 章节,可以知道:
0x95 和 0x88 是 Lead Byte,0x32 和 0x38 是 Trail Byte,他们符合 DBCS 的编码规则,同时也符合 MBCS 的规则;
• UNICODE 系列编码:UTF-8, UTF-16 的显示结果和编码值都是正确的,UTF-32 或 UCS4 只能用来转码,不能参与运算和显示,
这是因为 Windows 内核是 UTF-16 编码的,并不支持 UTF-32 和 UCS4,编译器也没有做,也认为没有必要做他们的显示和运算,
• GB18030 编码,只有定义为 AnsiStringT<54936> 类型,才能正常显示和参与运算,char * 只能做运算,无法直接显示。
测试程序的结论:
• 程序里面所有的字符都采用 AnsiStringT<54936> 很麻烦,
其次 GB18030 编码,包括 MBCS 的弱点,很难处理两个双字节拼成的四字节字符的 “半个汉字” 问题,因为这两半的编码没有任何区别,
• 通过 UNICODE 支持,非常简单:
只要不输出到文件,或者透过通讯传输数据,根本就不知道程序内部是什么编码的,
如果非得要 GB18030 编码的文件,存盘的时候给他转个编码,只要给 AnsiStringT<54936> 类型的字符串赋值再保存就可以了。
BIG5: 台湾、香港和澳门地区最常用的编码,共收录 13,060 个汉字。
• BIG5 为 DBCS 双字节字符集,对应于代码页 Code Page 950。
• 编码为大端存储 (Big Endian) ,Lead Byte 的范围:0x81 ~ 0xFE,Trail Byte 的范围:0x40-0x7E, 0xA1-0xFE。
• 如果一个汉字的简体字和繁体字写法不同,那么这个汉字只收录了繁体字,没有收录简体字,所以简体中文的文字,需要把简繁写法不同的字转成繁体,才能转为 BIG5 码,否则这些字会丢失。
• 把 BIG5 编码的文字转为 GBK,可以只进行编码转换,不用简繁体转换也不会丢失文字,因为 GBK 已经包含了 BIG5 里面的繁体字。
代码页 (Code Page)
代码页有很多,以下是常见的代码页。
| 代码页 Code Page | 说明 |
| CP_ACP = 0 |
ANSI 编码代码页 (ANSI code page), ANSI 本地编码:中国大陆:936, 中国港台:950,美国:1252,…… |
| CP_OEMCP = 1 |
OEM 代码页 (OEM code page), ASCII/DOS 本地编码:中国大陆:936, 中国港台:950,美国:437,…… |
| CP_MACCP = 2 |
Macintosh 代码页 (MAC code page),早期的苹果代码页 |
| CP_THREAD_ACP = 3 |
当前线程的 ANSI 代码页 (Current thread's ANSI code page) |
| CP_SYMBOL = 42 |
符号 (SYMBOL) |
| 437 |
ASCII (美国信息交换标准代码), DOS-USA,正宗的 ASCII 是美国的编码,不支持汉字或其他国家文字的!
两个 ASCII 表示一个汉字是 CP_ACP / CP_OEMCP 即 ANSI / ASCII 本地编码。 |
| 850 |
DOS 拉丁语 (DOS-LATIN1) |
| 936 |
GBK (国标扩展码/国标码), 中国大陆 (Chinese Main Land),新加坡 (Singapore) |
| 950 |
BIG5 (大五码), 中国台湾 (Chinese Taiwan), 中国香港 (Chinese Hongkong) |
| 932 |
Shift-JIS, 日语 (Japanese) |
| 949 |
韩国语 (Korean) |
| 874 |
泰国语 (Thai) |
| 1200 |
UTF-16 |
| 1201 |
UTF-16BE (UTF-16 Big Endian) |
| 1250 |
东欧 (Eastern Europe) |
| 1251 |
西里尔 Windows 系统 (Cyrillic Windows),俄语 Windows 系统 |
| 1252 |
西方语言-拉丁语1 (Western Latin 1),美国 Windows 用的是 1252,美国 DOS 用的是 437 (ASCII) |
| 1253 |
希腊语 (Greek) |
| 1254 |
土耳其语 (Turkish) |
| 1255 |
希伯来语 (Hebrew),以色列 |
| 1256 |
阿拉伯语 (Arabic) |
| 1257 |
波罗的海 (Baltic),立陶宛、拉脱维亚、爱沙尼亚等 |
| 1258 |
越南语 (Vietnamese) |
| 20866 |
西里尔/斯拉夫8位编码,Cyrillic KOI8-R,俄语、保加利亚语等 |
| 20936 |
简体中文 GB2312,早期汉字编码,现在多数情况都使用 936 代码页 |
| 54936 |
简体中文 GB18030,在 GBK 双字节编码的基础上,增加了 4 个字节的汉字编码,总共收录了 70,244 个汉字。
现在多数情况都使用 936 代码页,CP 54936 有很大的兼容性问题,要使用更多汉字编码的情况,一般都采用 UNICODE 的 CJK/CJKV 统一编码,收录了更多的汉字,而且提供了更好的兼容性 (全世界统一的编码)。 |
| CP_UTF7 = 65000 |
UTF-7 |
| CP_UTF8 = 65001 |
UTF-8 |
| 65005 |
UTF-32 |
| 65006 |
UTF-32BE (UTF-32 Big Endian) |
为什么要用 UNICODE?那么多年的 ANSI 用着不是挺好的吗?请看 →_→ UNICODE 和 ANSI 比较,哪个更好?
|