UNICODE / CJK / CJKV / UTF-7 / UTF-8 / UTF-16 / UTF-16LE / UTF-16BE / UTF-32 / UTF-32LE / UTF-32BE /
UCS2 / UCS2LE / UCS2LE / UCS4 / UCS4LE / UCS4BE / GB13000
| 编码 |
每个字符
的字节数 |
BOM
字节顺序标记 |
描述 |
| UNICODE |
只是字符编码,不是在电脑里面的文字存储格式 |
|
UNICODE (统一码、万国码、单一码) 为世界上所有语言的文字进行统一编码,可以跨语言、跨平台进行文字处理。UNICODE 给每一个字符都规定一个唯一的整数值作为编码,每个国家的文字都在不同的数值范围,除此之外,还包含了一些图形和符号。
• UNICODE 编码的值,通常用 U+十六进位制的数值来表示,例如小写英文字母 “a” 的编码为 U+0061,汉字的 “字” 编码为 U+5B57,表情符号 “😁” 的编码为 U+1F601。
• 由于整个地球上的文字数量太大了,UNICODE 收录的文字编码达到了 3 个字节表示的范围了,用 4 个字节的长整数表示一个字符浪费空间,用 2 个字节的短整数还不够用,于是就产生了各种储存文字的编码方式。例如有些设备的字节是 7 位的,不支持 8 位的字节,那么就产生了 UTF-7,把 UNICODE 编码按照一定的规则分成 7 位一组的数据,再储存在电脑里面。而 UTF-8 是按照一定规则,分解为 8 位一组的字节,储存在电脑里面。
• 在 Windows 系统里面,通常把 UTF-16 编码称为 UNICODE,而把本地编码称为 ANSI |
| CJK/CJKV |
UNICODE 里面的汉字编码,不是电脑里面的文字存储格式 |
|
CJK/CJKV 是 UNICODE 里面的汉字统一编码。
• CJK = CJK Unified Ideographs 中日韩统一表意文字。
• CJKV = CJKV Unified Ideographs 中日韩越统一表意文字。
CJK/CJKV 当中的
C = 汉语 (Chinese)、J = 日语 (Japanese)、K = 朝鲜语 (Korean)、V = 越南语 (Vietnamese)
• 我们经常说 CJK 而很少说 CJKV 是因为越南废止了汉字,他们把越文汉字和喃字加入了 UNICODE 统一编码的时候,大家已经在实际应用中使用 CJK 了。
编码规则:
• C,J,K,V 四种语言同一种写法的文字,在 UNICODE 里面是同一个编码,认为他们是同一个字,例如 “中” 字,在不同语言里面的写法都一样,他们是同一个字
• 同一个字有几种不同写法,会分开为几个不同的编码,认为他们不是同一个字,例如 “戶”、“户”、“戸” 和 “強”、“强”,因为写法不同,认为它们是不同的字,他们采用不同的编码。这不仅仅出现在汉字,英语也有同样现象,例如 “a”、“ɑ” 和 “g”、“ɡ”,甚至还收录了手写体 “𝒶” 和 “ℊ”,还有 CJK 地区使用的全形(全角)字母 “a” 和 “g”。 |
| UTF-7 |
1, 2⅔, 5⅓ |
2B 2F 76
38/39/2B/2F |
为了在只有 7 位字节的字符,不支持 8 位字节字符的设备或软件上使用 UNICODE 编码而产生的,这些都是比较老的设备,现在也许只有一些邮件系统,为了兼容老版本协议,还保留了这个编码。这个编码还有很多安全漏洞。为什么字节数不是整数值?UTF-7 的单字节字符 (英文字母、数字、一部分标点符号) 是 1 个字节的,其他字符先进行 UTF-16 编码,再进行 Base64 编码,如果 UTF-16 上是 2 个字节,Base64 之后就变成了 16/6 个字节,UTF-16 上是 4 个字节 Base64 之后就变成了 32/6 个字节了。 |
| UTF-8 |
1 ~ 4 |
EF BB BF |
目前应用最广泛的,最为火爆的编码,跨语言、跨平台的文字都采用 UTF-8 编码。每个字符 1 ~ 4 个字节,例如 "C" 是 1 个字节的,"©" 和 "β" 是 2 个字节的,"字" 和 "の" 是 3 个字节的,"𠀾" 和 "😁" 是 4 个字节的。C 语言里面可以用 char 数组或 char * 指针储存 UTF-8 编码的文字,这样即使用了 UNICODE 编码,又兼了容早期的 C 语言库函数。 |
| UTF-16 |
2 或 4 |
FF FE |
UTF-16 是 Windows 内核的文字编码方式,Windows 里面的宽字符 wchar_t 是这个编码的。从 Windows 2000 开始,操作系统内核都改为 UTF-16 编码了,所有的 API 函数也是以 UTF-16 编码为基础的。由于 UNICODE 编码需要 3 个字节表示,而 UTF-16 编码以 2 个字节的 char16_t 进行编码,那么每个字符就由 1 个或 2 个 char16_t 组成的,也就是每个字符 2 个或 4 个字节。单个 char16_t 的字符包括了常用的文字、图形和符号,双 char16_t 的字符包括了不常用的文字和表情或图形符号等。 例如 "C"、"©"、"β"、"字" 和 "の" 都是 2 个字节的,"𠀾" 和 "😁" 是 4 个字节的。 |
| UTF-16LE |
2 或 4 |
FF FE |
和 UTF-16 一样。LE 指的是小端存储 (Little Endian) |
| UTF-16BE |
2 或 4 |
FE FF |
编码规则和 UTF-16 一样,但是大端存储的 (Big Endian),高位字节在前,低位字节在后。这样,从储存在电脑里面的数据来看,和 UTF-16LE 之间比较,UTF-16BE 都是两两字节交换位置存储的。 |
| UTF-32 |
4 |
FF FE 00 00 |
UNICODE 编码是 3 个字节的,那么用 4 个字节的长整数储存肯定没问题,UTF-32 就是用 4 个字节的 char32_t 表示一个字符,每个字符都是 4 个字节的,数值正好等于 UNICODE 编码的值,不需要另外规定拆分和组合的规则。Linux 的宽字符 wchar_t 是这个编码的。 |
| UTF-32LE |
4 |
FF FE 00 00 |
和 UTF-32 一样。LE 指的是小端存储 (Little Endian) |
| UTF-32BE |
4 |
00 00 FE FF |
编码规则和 UTF-32 一样,但是大端存储的 (Big Endian),高位字节在前,低位字节在后。这样,从储存在电脑里面的数据来看,和 UTF-32LE 之间比较,UTF-32BE 都是每 4 个字节反向顺序存储的。 |
| UCS2 |
2 |
FF FE |
每个字符都是 2 个字节的。早期的 UNICODE 编码方式,刚开始定 UNICODE 编码标准的时候,认为 2 个字节足够表示所有的字符了。后来发现 2 个字节不够用了,为了兼容原来的 UCS2 编码,产生了 UTF-16,在原来的 UCS2 不变的基础上,增加 2 个 char16_t 的编码,即每个字符 4 个字节,用来存放增加的内容,不常用的文字都放在了 4 个字节的编码里面了。 |
| UCS2LE |
2 |
FF FE |
和 UCS2 一样。LE 指的是小端存储 (Little Endian) |
| UCS2BE |
2 |
FE FF |
编码规则和 UCS2 一样,但是大端存储的 (Big Endian), 高位字节在前,低位字节在后。这样,从储存在电脑里面的数据来看,和 UCS2LE 之间比较,UCS2BE 都是两两字节交换位置存储的。 |
| UCS4 |
4 |
FF FE 00 00 |
编码规则和 UTF-32 一样。由于 UCS2 编码不够用了,就产生了 4 个字节的编码 UCS4。这样很浪费空间,就产生了很多每个字符采用不同字节数的编码,即 UTF 系列编码,例如 UTF-8、UTF-16,按照这个规则,UCS4 这个编码,也就有了一个新的名字:UTF-32。 |
| UCS4LE |
4 |
FF FE 00 00 |
和 UCS4 一样,LE 指的是小端存储 (Little Endian) |
| UCS4BE |
4 |
00 00 FE FF |
编码规则和 UCS4 一样,但是大端存储的 (Big Endian),高位字节在前,低位字节在后。这样,从储存在电脑里面的数据来看,和 UCS4LE 之间比较,UCS4BE 都是每 4 个字节反向顺序存储的。 |
| GB13000-1993 |
2 |
|
是 UCS2 编码的一部分,这部分编码就是 GBK 编码的文字,按照 UCS2 重新编码而成。 |
| GB13000-2010 |
2, 4 |
|
是 UTF-16 编码的一部分,这部分编码就是 GBK 编码的文字,按照 UTF-16 重新编码而成。
虽说这样的结果和之前的 GB13000-1993 一模一样,但是 UTF-16 允许 4 个字节的编码,这就给增加文字预留了很大的空间。 |
UTF-16 和 UCS2 的区别:
• UTF-16 兼容 UCS2,是 UCS2 的升级版本。
• UTF-16 是变长编码,每个字符 2 或 4 个字节,其中 2 个字节的编码包含了所有的 UCS2 编码。
• UCS2 是定长的编码,每个字符固定 2 个字节,他们都包含在 UTF-16 的 2 字节编码里面了。
UTF-32 和 UCS4 的区别:
• 目前来看他们的编码完全相同,都是定长编码,每个字符 4 个字节,编码值等于 UNICODE 码值。
• 从名字来看,UTF-32 允许变长编码,UCS4 是定长编码,但是从现在的设计来看,没有打算也认为没有必要使用超过 4 个字节的 UNICODE 编码,所以认为这两个编码始终是相同的。
编码值测试程序及其他说明:
• GB18030 编码测试程序,包括了 UTF-8, UTF-16, UTF-32 和 GB18030 之间的编码转换与显示。
• 字符编码之间转换的章节内容。
BOM (Byte Order Mark) 字节顺序标记
这么多种类的 UNICODE 编码储存的文件或字符流,程序很难识别文件是哪种编码的,所以用字符 U+FEFF 作为文件或流的第一个字符,这个字符称为 “字节顺序标记”,英文名为 “BOM (Byte Order Mark)”。每种编码,这个字符编码后的内容都不同,只要识别文件或流前面几个字节就知道文件的编码了。
U+FEFF 即编码值为 0xFEFF 的字符:0 宽度、无间断的空白字符,Zero Width No-Break Space (BOM, ZWNBSP);
U+FFFE 这个编码的字符不存在,所以看到了前面两个字节是 FF FE 肯定就是 0xFEFF 的小端存储,而不是 0xFFFE 的大端存储。
例如 BOM 字符的 UTF-8 编码为 EF BB BF,看到文件或流的前面是这 3 个字节,那么就是 UTF-8 编码的。
所有的 BOM 的列表在 UNICODE 编码类型的表格里面。
UNICODE 编码
• UNICODE (统一码、万国码、单一码) 为世界上所有语言的文字进行统一编码,可以跨语言、跨平台进行文字处理。
• UNICODE 给每一个字符都规定一个唯一的整数值作为编码,每个国家或地区的文字都在不同的数值范围,除此之外,还包含了一些图形和符号。
• UNICODE 编码的值,通常用 U+十六进位制的数值来表示,
例如小写英文字母 “a” 的编码为 U+0061,汉字的 “字” 编码为 U+5B57,表情符号 “😁” 的编码为 U+1F601。
UNICODE 平面,基本多语言平面 (BMP),辅助平面
UNICODE 编码的编码空间为 0x0000 ~ 0x10FFFF,一共 1,114,112 个码位 (code point),
其中 U+D800 ~ U+DFFF 一共 2048 个码位不映射字符,所以用来映射字符的码位一共有 1,112,064 个。
平面 (Plane):UNICODE 的编码空间划为 17 个平面,每个平面 2¹⁶ = 65,536 个码位,
每个平面的编码空间为 U+nn0000 ~ U+nnFFFF,nn 为平面编号,从 0x00 到 0x10,即 0 ~ 16,一共 17 个。
第 0 个平面,Plane 0,称为基本多语言平面 (BMP, Basic Multilingual Plane)
其他平面,Plane 1 ~ 16,称为辅助平面 (Supplementary Planes)
基本多语言平面 (BMP) 内的 U+D800 ~ U+DFFF 这 2048 个码位不映射字符,UTF-16 利用这个区段的码位来对辅助平面的字符进行编码。
CJK 中日韩统一表意文字 (CJK Unified Ideographs)
CJK/CJKV 是 UNICODE 里面的汉字统一编码,C = 汉语 (Chinese)、J = 日语 (Japanese)、K = 朝鲜语 (Korean)、V = 越南语 (Vietnamese)
• CJK = CJK Unified Ideographs 中日韩统一表意文字。
• CJKV = CJKV Unified Ideographs 中日韩越统一表意文字。
• 我们经常说 CJK 而很少说 CJKV 是因为越南废止了汉字,他们把越文汉字和喃字加入 UNICODE 的时候,大家已经在实际应用中使用 CJK 了。
编码规则:
• C,J,K,V 四种语言同一种写法的文字,在 UNICODE 里面是同一个编码,认为他们是同一个字,
例如 “中” 字,在不同语言里面的写法都一样,他们是同一个字
• 同一个字有几种不同写法,会分开为几个不同的编码,认为他们不是同一个字,
例如 “戶”、“户”、“戸” 和 “強”、“强”,因为写法不同,认为它们是不同的字,他们采用不同的编码。
这不仅仅出现在汉字,英语也有同样现象,例如 “a”、“ɑ”、“𝒶” 和 “g”、“ɡ”、“ℊ”,还有 CJK 地区使用的全形(全角)字母 “a” 和 “g”。
目前为止,UNICODE 里面收录的 CJK 汉字个数达到了八万多字,根据下面表格统计,一共 80376 个汉字。
• 最基本的 CJK 统一汉字 (CJK Unified Ideographs) 是最初收录在 UNICODE 里面的 20950 个汉字,
编码范围 U+4E00 ~ U+9FD5,在 UNICODE 的 BMP 基本多语言平面里面;
• 后来在 BMP 里面又增加了一部分遗漏的常用汉字和一些不常用的汉字,称为 CJK 扩展 A 组,
编码范围 U+3400 ~ U+4DB5,一共 6582 个汉字;
• 最大数量的不常用的汉字在 CJK 扩展 B 组里面,42711 个汉字,编码范围 U+20000 ~ U+2A6D6,
由于这一组汉字数量非常大,放在了 UNICODE 辅助平面里面;
• 后续的补充遗漏的汉字的工作,在 UNICODE 的辅助平面里面,又陆续增加了扩展 C 组、扩展 D 组、扩展 E 组;
这些汉字的编码范围和字数在下面表格里面:
| 分组 |
中日韩统一表意文字分组 |
UNICODE 编码范围 |
汉字个数 |
| CJK 统一汉字 (基本) |
CJK Unified Ideographs |
U+4E00 ("一") ~ U+9FD5 ("鿕") |
20950 个汉字 |
| CJK 统一汉字扩展 A 组 |
CJK Unified Ideographs Extension A |
U+3400 ("㐀") ~ U+4DB5 ("䶵") |
6582 个汉字 |
| CJK 统一汉字扩展 B 组 |
CJK Unified Ideographs Extension B |
U+20000 ("𠀀") ~ U+2A6D6 ("𪛖") |
42711 个汉字 |
| CJK 统一汉字扩展 C 组 |
CJK Unified Ideographs Extension C |
U+2A700 ("𪜀") ~ U+2B734 ("𫜴") |
4149 个汉字 |
| CJK 统一汉字扩展 D 组 |
CJK Unified Ideographs Extension D |
U+2B740 ("𫝀") ~ U+2B81D ("𫠝") |
222 个汉字 |
| CJK 统一汉字扩展 E 组 |
CJK Unified Ideographs Extension E |
U+2B820 ("𫠠") ~ U+2CEA1 ("𬺡") |
5762 个汉字 |
这些汉字,一共 80376 个,每个分组的首尾部分的截图 (点击可以放大查看):
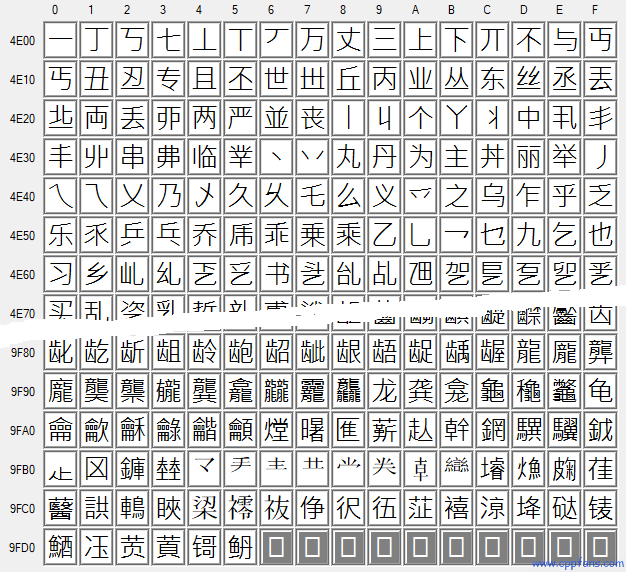
CJK Unified Ideographs
U+4E00 ("一") ~ U+9FD5 ("鿕")
CJK 统一汉字 (基本):20950 个汉字 |
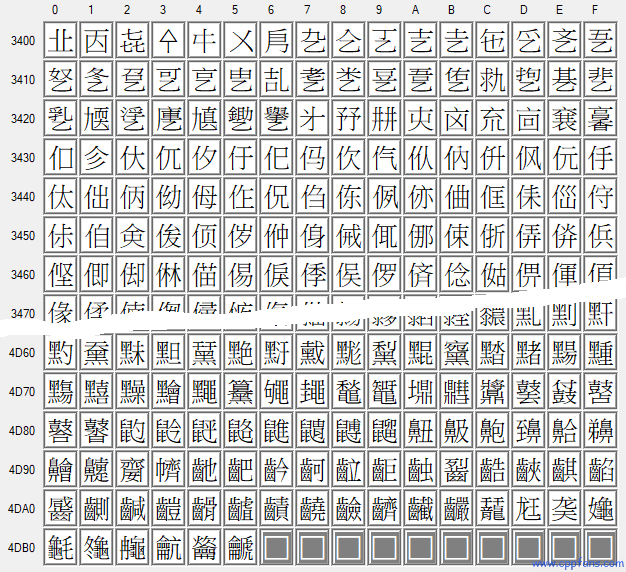
CJK Unified Ideographs Extension A
U+3400 ("㐀") ~ U+4DB5 ("䶵")
CJK 统一汉字扩展 A 组:6582 个汉字 |
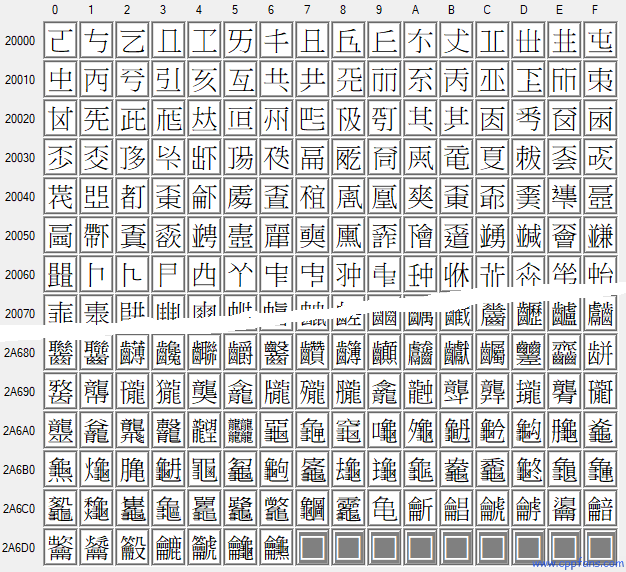
CJK Unified Ideographs Extension B
U+20000 ("𠀀") ~ U+2A6D6 ("𪛖")
CJK 统一汉字扩展 B 组:42711 个汉字 |
|
|
|
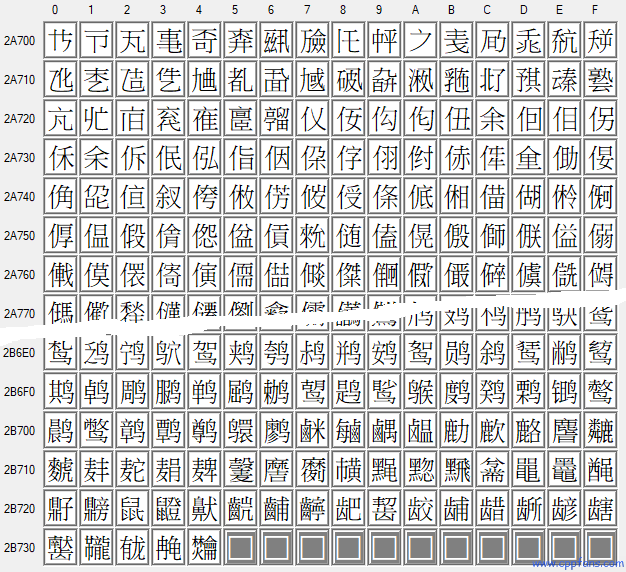
CJK Unified Ideographs Extension C
U+2A700 ("𪜀") ~ U+2B734 ("𫜴")
CJK 统一汉字扩展 C 组:4149 个汉字 |

CJK Unified Ideographs Extension D
U+2B740 ("𫝀") ~ U+2B81D ("𫠝")
CJK 统一汉字扩展 D 组:222 个汉字 |
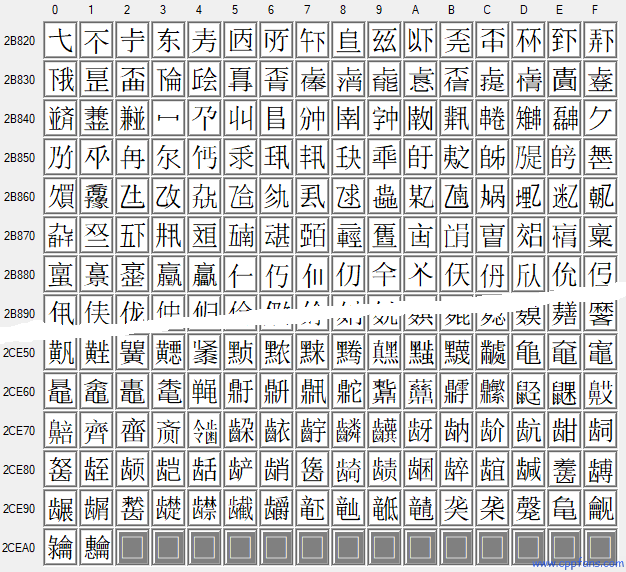
CJK Unified Ideographs Extension E
U+2B820 ("𫠠") ~ U+2CEA1 ("𬺡")
CJK 统一汉字扩展 E 组:5762 个汉字 |
示例程序:
 判断字符串里面的字符是否为汉字,获取汉字的 CJK 分组,计算代理对的 UNICODE 编码值 判断字符串里面的字符是否为汉字,获取汉字的 CJK 分组,计算代理对的 UNICODE 编码值
获取字符串里面汉字的个数和第几个字符是汉字
获取字符串里面的汉字所在的 CJK 分组
UTF-16 编码
字节类型 - 代理对、前导代理、后尾代理
UTF-16 编码是 Windows 操作系统核心的字符编码,是 Windows 编程最常用的编码类型,
C++ Builder 使用 UnicodeString 处理 UTF-16 编码的字符串。
由于 UTF-16 采用 16 位的字符 char16_t 进行编码,UNICODE 的基本多语言平面 (BMP) 里面的字符,直接使用单个 char16_t 编码,编码值就等于 UNICODE 码值;而辅助平面里面的字符,使用一对 char16_t 进行编码,这一对 char16_t 称为代理对 (surrogate pair),这样的字符长度为 32 位,即 4 个字节。
生成代理对的方法:
• 代理对处理的编码范围:辅助平面的编码空间 0x10000 ~ 0x10FFFF,一共 1,048,576 个码位,
• 把这些码位的编码值都减去 0x10000,那么就是 0x0000 ~ 0xFFFFF 这个 20 位二进制长度表示的范围了,
• 把这 20 位的数值分成两段:高 10 位和低 10 位,他们的范围都是 0x0000 ~ 0x03FF,
• 高 10 位 0x0000 ~ 0x03FF 加上 0xD800 得到 0xD800 ~ 0xDBFF,称为高位代理 (high surrogate),
• 低 10 位 0x0000 ~ 0x03FF 加上 0xDC00 得到 0xDC00 ~ 0xDFFF,称为低位代理 (low surrogate)。
高位代理和低位代理没有重复的编码,所有的高位代理的编码值都比低位代理的数值小,这些编码值正好在基本多语言平面里面的预留编码范围。
为了避免使用上的混淆,现在的 UNICODE 标准把高位代理称为前导代理 (lead surrogate),把低位代理称为后尾代理 (trail surrogate)。
根据以上的 UTF-16 编码规则,每个 char16_t 字符就有 3 种类型:
• 单个 char16_t 的基本多语言平面 (BMP) 字符,取值范围:0x0000 ~ 0xD7FF 和 0xE000 ~ 0xFFFF
• 前导代理 (lead surrogate),取值范围:0xD800 ~ 0xDBFF
• 后尾代理 (trail surrogate),取值范围:0xDC00 ~ 0xDFFF
这 3 种类型的字符没有重叠的编码值,这样就可以简单的根据取值范围来判断类型。
| 前导代理 = 0xD800 + (0x03FF & ((编码值 - 0x10000) >> 10)); |
| 后尾代理 = 0xDC00 + (0x03FF & (编码值 - 0x10000)); |
| 编码值 = 0x10000 + (((前导代理-0xD800)<<10) | (后尾代理-0xDC00)); |
例1:解析字符串 L"没𠕇😲"
| 字符串内容 |
|
|
|
| 字节类型 |
|
|
|
| UNICODE 编码 |
U+6CA1 |
U+20547 |
U+1F632 |
| 字符 |
没 |
𠕇 |
😲 |
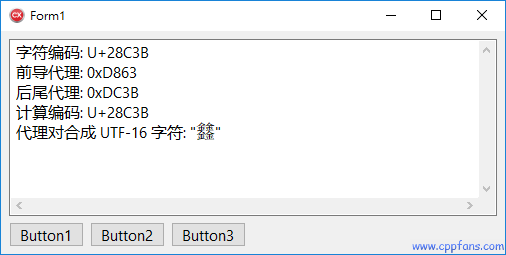
例2:计算代理对 (前导代理、后尾代理)、通过代理对计算编码值,通过代理对生成字符串:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
char32_t cChar = U'𨰻'; // UTF-32 的字符值就是 UNICODE 编码值
char16_t cLead = 0xD800 + (0x03FF & ((cChar - 0x10000) >> 10)); // 计算前导代理
char16_t cTrail = 0xDC00 + (0x03FF & (cChar - 0x10000) ); // 计算后尾代理
char32_t cCode = 0x10000 + (((cLead - 0xD800)<<10) | (cTrail-0xDC00)); // 通过代理对计算 UNICODE 编码值
char16_t cStr[] = { cLead, cTrail, 0 }; // 通过代理对生成 UTF-16 字符
UnicodeString s;
s.cat_sprintf(L"字符编码: U+%04X\r\n", cChar );
s.cat_sprintf(L"前导代理: 0x%04X\r\n", cLead );
s.cat_sprintf(L"后尾代理: 0x%04X\r\n", cTrail);
s.cat_sprintf(L"计算编码: U+%04X\r\n", cCode );
s.cat_sprintf(L"代理对合成 UTF-16 字符: \"%s\"\r\n", cStr);
Memo1->Text = s;
} |
UTF-16 其他示例程序:
例1:获取字符串长度、字符个数、每个字符的类型
例2:判断字符串里面的字符是否为汉字,获取汉字的 CJK 分组,计算代理对的 UNICODE 编码值
例2.1:获取字符串里面汉字的个数和第几个字符是汉字
例2.2:获取字符串里面的汉字所在的 CJK 分组
UTF-8 编码
• 目前应用最广泛的,最为火爆的编码,跨语言、跨平台的文字都采用 UTF-8 编码
• UTF-8 编码非常适合存储和传输,文字当中任何一个字节损坏都不影响其他字符的解码,不会引起乱码,
可以从一段文字中间的任何位置开始解析,不必知道是第几个字符,也不必知道是奇偶地址
• 每个字符 1 ~ 4 个字节,例如 "C" 是 1 个字节的,"©" 和 "β":2 个字节,"字" 和 "の":3 个字节,"𠀾" 和 "😁":4 个字节
• C 语言里面可以用 char 数组或 char * 指针储存 UTF-8 编码的文字,这样即使用了 UNICODE 编码,又兼了容早期的 C 语言库函数
UTF-8 编码是以字节为单位编码的,每个字节是 8 位二进制数,最高位有几个连续的 1 表示了每个字节的类型:
字节结构
“x” 为有效编码位 |
说明 |
字符总位数
(bits) |
字符的字节数
(bytes) |
UNICODE 编码范围 |
|
单字节字符 |
0 ~ 7 |
1 |
U+0000 ~ U+007F
基本多语言平面 (BMP) 前面单字节字符 |
|
多字节字符当中
与前面的字节组合在一起的字节 |
- |
- |
- |
|
二字节字符的首字节 |
8 ~ 11 |
2 |
U+0080 ~ U+07FF
基本多语言平面 (BMP) 中间部分字符 |
|
三字节字符的首字节 |
12 ~ 16 |
3 |
U+0800 ~ U+FFFF
基本多语言平面 (BMP) 后面部分字符 |
|
四字节字符的首字节 |
17 ~ 21 |
4 |
U+10000 ~ U+1FFFFF
所有 16 个辅助平面的字符 |
|
五字节字符的首字节 |
22 ~ 26 |
5 |
U+200000 ~ U+3FFFFFF
超出目前 UNICODE 编码规定的范围了 |
|
六字节字符的首字节 |
27 ~ 31 |
6 |
U+4000000 ~ U+7FFFFFFF
超出目前 UNICODE 编码规定的范围了 |
• 由于 1 ~ 4 个字节的字符涵盖了基本多语言平面 (BMP) 和 16 个辅助平面所有的字符,所以目前 UTF-8 编码没有 5 个以上字节数的字符;
• 字符需要尽可能的用更少的字节数编码,例如:虽然单字节字符用两个字节的编码也能做出来,但是那是错误的编码,同样,两个字节的字符用三个字节的编码表示也是错误的。上面表格里面的 “字符总位数” 和 “字符的字节数” 为参考数据。
例:“我” 字的 UTF-8 编码为 E6 88 91
E6: 11100110 → 最高位连续 3 个 1,说明一共是 3 个字节的字符,有效编码位:0110
88: 10001000 → 最高位连续 1 个 1,说明是跟前一个字节组合在一起,有效编码位:001000
91: 10010001 → 最高位连续 1 个 1,说明是跟前一个字节组合在一起,有效编码位:010001
三个字节的有效编码位组合在一起:0110 001000 010001 按照 4 位一组分组:0110 0010 0001 0001 得到十六进制的 6211
所以 “我” 字的 UNICODE 编码计算出来就是 U+6211
这么多的眼花缭乱的 UNICODE 编码,都看糊涂了,应该用哪个呀?
• UTF-8: 是最通用的编码,跨语言、跨平台的,无论是网页、xml 还是 json 等,都用的是 UTF-8,大多数的数据库也采用的 UTF-8 编码。
这个编码非常适合文字存储和传输,利用字节编码,容错能力非常的强,
· 做文字处理,有他强势的一面:可以使用老版本的字符处理方法。
利用老版本的字符处理,ANSI 寻找一个英文字母可能会定位到一个汉字里面,这绝对不会发生在 UTF-8 上,
因为 2 个字节以上的编码当中,是不包含单字节字符的,而 ANSI 的 Trail Byte 会包含英文字母,ANSI 必须用独特的一套函数来处理。
这在解析 html, xml 和 json 的时候,UTF-8 非常的简单、高效,而 ANSI 经常会出错,而且效率低。
· 做文字处理,有他弱势的一面:统计文字个数,或者需要第几个字符的内容的时候,就比较麻烦了,因为每个字符的字节数都不等。
• UTF-16: Windows 里面写程序最常用的当然用的是 UTF-16 了,因为 Windows API 函数是基于 UTF-16 的。
但是,要和其他操作系统或语言进行数据交流,UTF-16 是不行的,只有 Windows 核心用了 UTF-16,其他的操作系统用起来非常麻烦的。
依照最初的字符编码想法是采用 UCS2 的,可以由于收录的文字不断增加,扩展为 UTF-16,这也为不常用的文字的处理带来一些困难。
· 在 Windows 里面,一般都是用 UTF-16 处理文字,用 UTF-8 存储或传输,
· 由于 xml, json, html 等 UTF-8 的解析方法很成熟了,Windows 里面解析这些文件也经常直接采用 UTF-8 编码的这些库或函数。
· 我的 Windows 版本程序是 UTF-16 编码的吗?请看这里:设置项目的 UNICODE / ANSI 版本。
• UTF-32: Linux 或其他非微软平台使用的编码,由于文字编码就是 UNICODE 编码本身,处理文字是最简单的了。
在 Linux 里面,宽字符函数都是基于 UTF-32 编码的,可以用这个处理文字,用 UTF-8 存储或传输。
• 所有其他编码,无论是 UNICODE 系列还是 ANSI 系列的编码,都不在文字处理里面使用,如果用户需要,最终的数据给他转个编码。
为什么要用 UNICODE?那么多年的 ANSI 用着不是挺好的吗?请看 →_→ UNICODE 和 ANSI 比较,哪个更好?
|