使用字符串变量之间自动转码
经常用到的 C++ Builder 的字符串变量类型:
| 变量类型 |
编码 |
说明 |
| UnicodeString |
UTF-16 |
C++ Builder 最常用的字符串类型,大多数控件的字符串类型的属性都是这个类型的 |
| UTF8String |
UTF-8 |
应用非常多的类型 |
| AnsiString |
ANSI 本地编码 |
为了兼容 ANSI 编码保留下来的字符串类型,曾经是应用最多的类型。 |
| AnsiStringT<CP> |
CP 代码页的编码 |
支持所有以 char 为基础的编码,即包含单字节字符的编码,包括 ANSI 和 UTF-7, UTF-8;
不支持宽字符编码,比如 UTF-16, UTF-32, GB13000 |
以上字符串变量类型之间可以互相赋值,它们会自动进行编码转换。
• 常用的编码用 UnicodeString, UTF8String 和 AnsiString, 不常用的编码用 AnsiStringT, 例如 AnsiStringT<CP_UTF7>
• AnsiStringT<CP_UTF8> 和 UTF8String 是等效的,AnsiStringT<CP_ACP> 和 AnsiString 是等效的
• AnsiStringT 也不是百分之百万能的,因为他不能代替 UnicodeString。
字符串编码转换的例子:UTF-16, UTF-8, ANSI, GBK, BIG5 之间进行字符编码转换
void __fastcall TForm1::Button1Click(TObject *Sender)
{
UnicodeString utf16 = L"中国"; // 原始的 UTF-16 字符串
UTF8String utf8 = utf16; // UTF-16 转 UTF-8
AnsiStringT<936> gbk = utf8; // UTF-8 转 GBK
AnsiString ansi = utf16; // UTF-16 转 ANSI
Memo1->Lines->Add(L"原始的 UTF-16: " + utf16);
Memo1->Lines->Add(L"UTF-16 转 UTF-8: " + utf8 );
Memo1->Lines->Add(L"UTF-8 转 GBK: " + gbk );
Memo1->Lines->Add(L"UTF-16 转 ANSI: " + ansi );
AnsiStringT<950> big5 = gbk; // GBK 直接转 BIG5
Memo1->Lines->Add(L"GBK 直接转 BIG5: " + big5);
big5 = CHS2CHT(gbk); // GBK 转繁转 BIG5
Memo1->Lines->Add(L"GBK 转繁转 BIG5: " + big5);
gbk = big5; // BIG5 直接转 GBK
Memo1->Lines->Add(L"BIG5 直接转 GBK: " + gbk);
gbk = CHT2CHS(big5); // BIG5 转简转 GBK
Memo1->Lines->Add(L"BIG5 转简转 GBK: " + gbk);
AnsiStringT<20936>gb2312 = big5; // BIG5 直接转 GB2312
Memo1->Lines->Add(L"BIG5 直接转 GB2312: " + gb2312);
gb2312 = CHT2CHS(big5); // BIG5 转简转 GB2312
Memo1->Lines->Add(L"BIG5 转简转 GB2312: " + gb2312);
} |
运行结果:
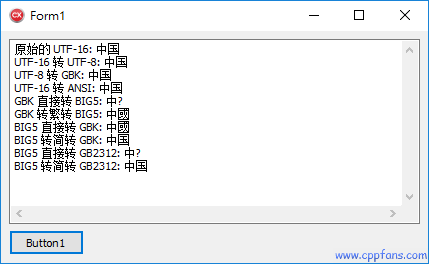
结论:各个编码之间转换,只要转换后的编码包含字符串里面所有文字的编码就能成功,否则会丢失缺少的文字。
• BIG5 里面没有简体的 “国”,所以直接把 “中国” 转成 BIG5 就变成了 “中?”,用 CHS2CHT 函数转成繁体就没问题了。
• GB2312 里面没有繁体的 “國”,所以直接把 “中國” 转成 GB2312 就变成了 “中?”,用 CHT2CHS 函数转成简体就没问题了。
使用 TStringList 读写文件时指定编码的方法对文件进行字符编码转换
查看 TStringList 类的详细说明请点击这里。
把 ANSI 本地编码的文件转为 UTF-8 编码的文件
#include <memory>
void __fastcall TForm1::Button3Click(TObject *Sender)
{
std::auto_ptr<TStringList>sl(new TStringList);
sl->LoadFromFile(L"d:\\ansifile.txt", TEncoding::ANSI);
sl->SaveToFile(L"d:\\utf8file.txt", TEncoding::UTF8);
} |
把 BIG5 编码的文件转为 GBK 编码的文件
#include <memory>
void __fastcall TForm1::Button1Click(TObject *Sender)
{
std::auto_ptr<TStringList>sl(new TStringList);
std::auto_ptr<TEncoding>encBig5(new TMBCSEncoding(950)); // 选取代码页 950
sl->LoadFromFile(L"d:\\big5file.txt", encBig5.get()); // 读取 BIG5 编码的文件
std::auto_ptr<TEncoding>encGBK(new TMBCSEncoding(936)); // 选取代码页 936
sl->SaveToFile(L"d:\\gbkfile.txt", encGBK.get()); // 存为 GBK 编码的文件
} |
把一个字符串 (或一段文字) 分别储存为 UTF-8, ANSI 本地编码和 BIG5 编码的文件。
因为 BIG5 编码不包含简体字,所以在保存为 BIG5 编码之前,进行了简转繁。
#include <memory>
void __fastcall TForm1::Button2Click(TObject *Sender)
{
std::auto_ptr<TStringList>sl(new TStringList);
sl->Text = L"中国汉字"; // 把这段文字存成几个不同编码的文件
sl->SaveToFile(L"d:\\utf8file.txt" , TEncoding::UTF8); // 存为 UTF-8 编码的文件
sl->SaveToFile(L"d:\\ansifile.txt" , TEncoding::ANSI); // 存为 ANSI 编码的文件
sl->SaveToFile(L"d:\\utf16file.txt", TEncoding::Unicode); // 存为 UNICODE (UTF-16) 编码的文件
sl->Text = CHS2CHT(sl->Text); // 简转繁
std::auto_ptr<TEncoding>encBig5(new TMBCSEncoding(950)); // 选择代码页 950
sl->SaveToFile(L"d:\\big5file.txt", encBig5.get()); // 存为 BIG5 编码的文件
} |
需要用函数进行 UTF-32 和 UCS4 编码转换
| 变量类型 |
编码 |
说明 |
| UCS4String |
UCS4, UTF-32 |
目前来看,UTF-32 和 UCS4 是相同的编码,详见 UNICODE 章节。
这个变量类型只用作编码转换和储存数据,不能直接参与更多的字符串运算。
把 UCS4String 显示出来,需要转成 UnicodeString 来显示,不支持直接显示 UCS4String。 |
编码转换函数:
把 UCS4String 转为 UnicodeString, 即 UTF-32 转为 UTF-16
UnicodeString __fastcall UCS4StringToUnicodeString(const UCS4String S);
把 UnicodeString 转为 UCS4String, 即 UTF-16 转为 UTF-32
UCS4String __fastcall UnicodeStringToUCS4String(const UnicodeString S);
编码转换例子程序:
请看 GB18030 编码的编码转换例子,这个例子利用 UCS4String 显示出来 UNICODE 编码的编码值。
使用 Windows API 函数进行字符编码转换
Windows API 函数只能在宽字符和 MBCS 之间转换,如果两个 ANSI 编码之间转换,必须用 MBCS → Wide → MBCS 这样两次转换的过程。
char *WideToMbcs(wchar_t *pWide, UINT uCodePage) // 返回值用完别忘了 delete
{
char *pMbcs = NULL;
int BufSize = WideCharToMultiByte(uCodePage, 0, pWide, -1, NULL, 0, NULL, NULL);
if(BufSize>0)
{
pMbcs = new char[BufSize];
WideCharToMultiByte(uCodePage, 0, pWide, -1, pMbcs, BufSize, NULL, NULL);
}
return pMbcs;
}
//---------------------------------------------------------------------------
wchar_t *MbcsToWide(char *pMbcs, UINT uCodePage) // 返回值用完别忘了 delete
{
wchar_t *pWide = NULL;
int BufSize = MultiByteToWideChar(uCodePage, 0, pMbcs, -1, NULL, 0);
if(BufSize>0)
{
pWide = new wchar_t[BufSize];
MultiByteToWideChar(uCodePage, 0, pMbcs, -1, pWide, BufSize);
}
return pWide;
}
//--------------------------------------------------------------------------- |
用 Windows API 函数进行编码转换的例子:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
char sAnsi[] = "中国";
wchar_t *pWide = MbcsToWide(sAnsi, CP_ACP); // ANSI 转 Wide (UTF-16)
if(pWide) // 转换成功
{
Memo1->Lines->Add(L"ANSI 转 Wide (UTF-16): " + String(pWide));
char *pUtf8 = WideToMbcs(pWide, CP_UTF8); // Wide (UTF-16) 转 UTF-8
if(pUtf8)
{
Memo1->Lines->Add(L"Wide (UTF-16) 转 UTF-8: " + UTF8String(pUtf8));
delete pUtf8;
}
char *pBig5 = WideToMbcs(pWide, 950); // Wide (UTF-16) 转 BIG5
if(pBig5)
{
Memo1->Lines->Add(L"Wide (UTF-16) 转 BIG5: " + AnsiStringT<950>(pBig5));
delete pBig5;
}
delete pWide;
}
} |
运行结果:
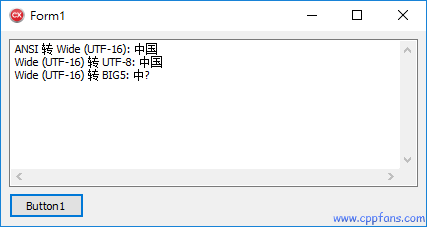
结论:
• 只要目标编码包含所有要转编码的字符,就能转换成功,由于 BIG5 里面没有简体的 “国”,所以变成了 “中?”。
• 如果要让所有的简体字都转为 BIG5 编码,就必须先把简体中文转成繁体中文,然后再转 BIG5。
简体中文和繁体中文之间转换
UnicodeString CHT2CHS(UnicodeString sChs) // 繁體转为简体: "漢語" → "汉语"
{
UnicodeString sDst;
LCID lcidSrc = MAKELCID(MAKELANGID(LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED), SORT_CHINESE_BIG5);
int iNewLen = LCMapString(lcidSrc, LCMAP_SIMPLIFIED_CHINESE, sChs.c_str(), sChs.Length(), NULL, 0);
if(iNewLen>0)
{
sDst.SetLength(iNewLen);
LCMapString(lcidSrc, LCMAP_SIMPLIFIED_CHINESE, sChs.c_str(), sChs.Length(), sDst.c_str(), iNewLen);
}
return sDst;
}
//---------------------------------------------------------------------------
UnicodeString CHS2CHT(UnicodeString sCht) // 简体轉為繁體: "汉语" → "漢語"
{
UnicodeString sDst;
LCID lcidSrc = MAKELCID(MAKELANGID(LANG_CHINESE, SUBLANG_CHINESE_SIMPLIFIED), SORT_CHINESE_PRC);
int iNewLen = LCMapString(lcidSrc, LCMAP_TRADITIONAL_CHINESE, sCht.c_str(), sCht.Length(), NULL, 0);
if(iNewLen>0)
{
sDst.SetLength(iNewLen);
LCMapString(lcidSrc, LCMAP_TRADITIONAL_CHINESE, sCht.c_str(), sCht.Length(), sDst.c_str(), iNewLen);
}
return sDst;
}
//--------------------------------------------------------------------------- |
使用以上两个函数,可以在简体中文和繁体中文之间互相转化:
void __fastcall TForm1::Button1Click(TObject *Sender)
{
Memo1->Lines->Add(CHT2CHS(L"漢語"));
Memo1->Lines->Add(CHS2CHT(L"中国"));
} |
运行结果:"漢語" 转成了 "汉语","中国" 转成了 "中國"。

|