把 UNICODE 字符转为 ANSI 编码,这个字符都可以对应那些 ANSI 代码页:
• 只支持基本多语言平面 (BMP) 的字符,即 UTF-16 编码当中的单个 16 位字符 (char16_t 或 wchar_t),
• 多数的 ANSI 编码也只是基本多语言平面 (BMP) 当中的一部分,包括 GBK 和 GB2312 编码,
• 不支持获取辅助平面里面的字符的 ANSI 代码页列表。
• 常见的 ANSI 编码当中 GB18030 涉及到了辅助平面里面的字符,这个方法不支持 GB18030 编码和 54936 代码页。
通过这个方法可以知道 UNICODE 字符串转为某个 ANSI 编码的时候,哪些字符会丢失。
#include <mlang.h>
void __fastcall TForm1::Button8Click(TObject *Sender)
{
UnicodeString s = L"Victor, 你好!❤δ€1²1㧟一壹㒰①㊄㈤☯";
IMLangCodePages *lpLangCodePages = NULL;
if(SUCCEEDED(CoCreateInstance(CLSID_CMultiLanguage, NULL, CLSCTX_INPROC_SERVER, IID_IMLangCodePages, (void**)&lpLangCodePages)))
{
for(int i=1; i<=s.Length(); i++)
{
wchar_t c = s[i];
DWORD dwcp = 0, dwcp1;
UINT uCodePage = 0;
lpLangCodePages->GetCharCodePages(c,&dwcp); // 获取字符 c 支持的所有的 ANSI 代码页
UnicodeString sCodePages;
while(dwcp) // 这个字符支持的所有的 ANSI 代码页
{
lpLangCodePages->CodePagesToCodePage(dwcp, CP_ACP, &uCodePage); // 获取代码页 uCodePage
lpLangCodePages->CodePageToCodePages(uCodePage, &dwcp1); // 获取代码页的位编码 dwcp1
dwcp&=~dwcp1; // 从 dwcp 里面去掉 dwcp1
sCodePages.cat_sprintf(sCodePages.IsEmpty()?L"%u":L", %u", uCodePage); // 输出代码页 uCodePage 值
}
sCodePages = String().sprintf(L"\"%c\": ",c) + sCodePages;
Memo1->Lines->Add(sCodePages);
}
lpLangCodePages->Release();
}
} |
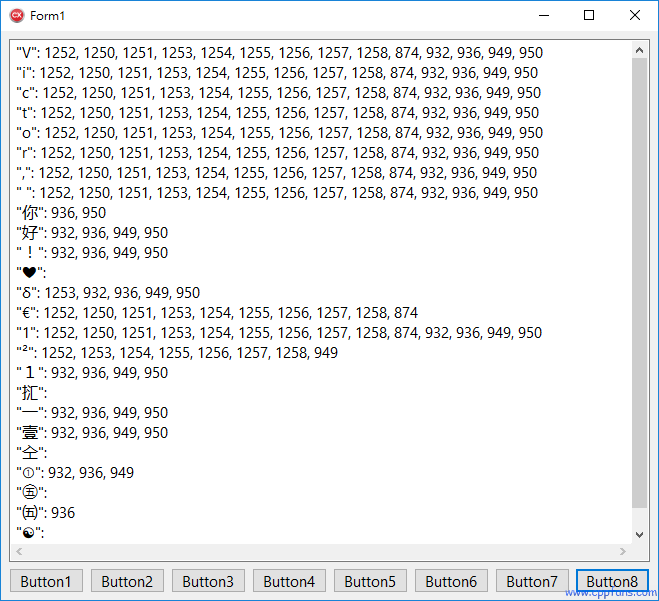
通过运行结果发现:
汉字 “你” 字,在简体中文 GBK (936) 和繁体中文 BIG5 (950) 的 ANSI 编码里面都有,但是日语 (932) 和韩国语 (949) 的 ANSI 里面没有,
汉字 “好” 字,在简体中文 GBK (936) 和繁体中文 BIG5 (950),日语 (932) 和韩国语 (949) 的 ANSI 编码里面都有,
汉字 “㧟” 字,在所有支持的 ANSI 编码里面都没有,所以支持的代码页为空白。
欧元符号 “€”,在中、日、韩的 ANSI 编码里面都没有。
UNICODE 转为 ANSI 编码的时候,转为任何一个 ANSI 编码都有可能会丢失数据。
|