函数原型:
TUnicodeCategory __fastcall GetUnicodeCategory(System::WideChar C);
TUnicodeCategory __fastcall GetUnicodeCategory(System::UCS4Char C);
TUnicodeCategory __fastcall GetUnicodeCategory(const System::UnicodeString S, int Index);
头文件:
#include <System.Character.hpp> (XE2 之后) #include <Character.hpp> (XE 之前)
参数:
C: 单个字符;
S: 字符串,index: 在字符串里面的字符序号,获取字符串 S 里面的第 index 个字符的类型。
注:如果获取单个字符的类型,可能会返回 ucSurrogate 代理对类型,
如果获取字符串里面的字符,不会返回 ucSurrogate 代理对这个类型,而是计算出代理对的 UNICODE 编码值,然后返回这个 UNICODE 字符的真实类型。
返回值:
TUnicodeCategory 枚举类型,可以是以下表格里面的值:
| 字符类型 |
描述 |
示例 |
| ucControl |
控制符 |
回车换行 "\r\n" |
| ucFormat |
格式符 |
U+202B Right-To-Left Embedding [RLE] |
| ucUnassigned |
未定义的。这个函数遗漏的,或者是新版本 UNICODE 新增的文字或符号 |
汉字 鿌鿍鿎鿏鿐鿑鿒鿓鿔鿕,字母 Ԭԯԧ,表情符号 😀😁😂😃😄,其他符号 ✅✨⮂⏰ 等 |
| ucPrivateUse |
专用区
可以存放自定义字符的区域 |
在平面 15 和平面 16 上各有 65534 个码位,
分别是 0xF0000 ~ 0xFFFFD 和 0x100000 ~ 0x10FFFD |
| ucSurrogate |
代理对字符
包括前导代理和后尾代理 |
基本多语言平面 (BMP) 里面的 U+D800 ~ U+DFFF 这段码位,
只有获取单个字符的时候会出现这个值,
如果对字符串进行解析,会解析到代理对表示的实际字符的类型 |
| ucLowercaseLetter |
小写字母 |
abcωπāáǎà 等 |
| ucModifierLetter |
修饰字母 |
ˇˆʾʿ 等 |
| ucOtherLetter |
不区分大小写的字母 |
汉字、阿拉伯文、朝鲜语、日语等 |
| ucTitlecaseLetter |
用于标题的大小写状态的字母 |
拉丁字母 DžLjNjDz 和希腊字母 ᾈᾏᾘᾟᾨᾯ 等 |
| ucUppercaseLetter |
大写字母 |
ABCΩΠĀÁǍÀ 等 |
| ucCombiningMark |
组合字符,很多组合字符会识别分类为ucEnclosingMark 和 ucNonSpacingMark |
ःािी 等 |
| ucEnclosingMark |
组合字符,没找到相关的说明,
测试结果:这些字符会和其他字符重叠在一起 |
字符 ҈ 插入在 “abc123汉字” 的每个字符之间:“a҈b҈c҈1҈2҈3҈汉҈字”
字符 ꙲ 插入在 “abc123汉字” 的每个字符之间:“a꙲b꙲c꙲1꙲2꙲3꙲汉꙲字” |
| ucNonSpacingMark |
组合字符,没有间距的标记 |
â 看上去是一个字符,其实是两个字符 a 和 ̂ ,他们挨在一起就组合在一起了。“̂ ” 就是没有间距的标记 (组合字符) |
| ucDecimalNumber |
十进制数 |
通用阿拉伯数字 0123456789,阿拉伯文数字 ٠١٢٣٤٥٦٧٨٩ 等 |
| ucLetterNumber |
字母数字 |
罗马数字 ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩⅪⅫ 和 ⅰⅱⅲⅳⅴⅵⅶⅷⅸⅹⅺⅻ 等 |
| ucOtherNumber |
其他数字 |
½¼¾ ¹²³ ₁₂₃ ①②③ ⑴⑵⑶ ❶❷❸ ㊀㊁㊂ 等 |
| ucConnectPunctuation |
连接标点符号 |
_‿⁀⁔︳︴﹍﹎﹏_ 等 |
| ucDashPunctuation |
划线标点符号 |
-֊־᐀᠆‐‑‒–—―⸗⸚〜〰゠︱︲﹘﹣- 等 |
| ucClosePunctuation |
结束标点符号 (括号) |
)]}〉》」』】〗﹀︾﹂﹄︼︘ 等 |
| ucFinalPunctuation |
结束标点符号 (引号) |
»’” 等 |
| ucInitialPunctuation |
开始标点符号 (引号) |
«‘“ 等 |
| ucOtherPunctuation |
其他标点符号 (不区分开始与结束的) |
!"'#%&*?,。 等 |
| ucOpenPunctuation |
开始标点符号 (括号) |
([{〈《「『【〖︿︽﹁﹃︻︗ 等 |
| ucCurrencySymbol |
货币符号 |
$¢£¤¥₤€ 等 |
| ucModifierSymbol |
修饰符号 |
^`¨¯´ 等 |
| ucMathSymbol |
数学符号 |
+<=>|~¬±×÷϶∀∂∃∄∅∆∇∈∉∏∑∘∝∞∟∠∡∢∩∪∫∬∭∮∯∰∴∵≈≉≌ 等 |
| ucOtherSymbol |
其他符号 |
©®°¶℗℡™℻⌂⌨☑☐☒☮☯♪⚽⚾✓✗ 等 |
| ucLineSeparator |
行分割符 |
U+2028 LINE SEPARATOR |
| ucParagraphSeparator |
段落分割符 |
U+2029 PARAGRAPH SEPARATOR |
| ucSpaceSeparator |
空格 |
中文排版经常用到的:
U+0020 SPACE [SP] 普通的空格,英文空格
U+3000 IDEOGRAPHIC SPACE 中文全角空格
还有其他的不同宽度或功能空格,
例如 U+00A0 NO-BREAK SPACE [NBSP] 不间断的空格和 U+2000 ~ U+200A 等 |
例:获取字符串长度、字符个数、每个字符的类型
#include <System.Character.hpp> // XE 之前为 #include <Character.hpp>
//---------------------------------------------------------------------------
void __fastcall TForm1::Button1Click(TObject *Sender)
{
UnicodeString sText = L"Ab€δ汉字螭𧉚𧈢𧏡123😊☯"; // 螭𧉚和𧈢𧏡常误写为螭吻和蚣蝮
int iLength = sText.Length();
int iCharCount = 0;
Memo1->Lines->Add(L"字符串长度:" + IntToStr(iLength) + L" (个 wchar_t)");
for(int i=1; i<=iLength; i++)
{
UnicodeString::TStringLeadCharType ct = sText.ByteType(i);
UnicodeString sInfo = L"第 "+ IntToStr(i) +L" 个 wchar_t: "+ EnumToStr(ct);
switch(ct)
{
case UnicodeString::ctNotLeadChar :
{
iCharCount++;
TUnicodeCategory uc = GetUnicodeCategory(sText, i);
sInfo += L", 第 " + IntToStr(iCharCount) + L" 个字符";
sInfo += L", 单独字符: \"" + sText.SubString(i,1);
sInfo += L"\", " + EnumToStr(uc);
} break;
case UnicodeString::ctbLeadSurrogate:
{
iCharCount++;
TUnicodeCategory uc = GetUnicodeCategory(sText, i);
sInfo += L", 第 " + IntToStr(iCharCount) + L" 个字符";
sInfo += L", 与后组为: \"" + sText.SubString(i,2);
sInfo += L"\", " + EnumToStr(uc);
} break;
case UnicodeString::ctTrailSurrogate:
{
sInfo += L", 与前组合";
} break;
}
Memo1->Lines->Add(sInfo);
}
Memo1->Lines->Add(L"一共 " + IntToStr(iCharCount) + L"个字符");
} |
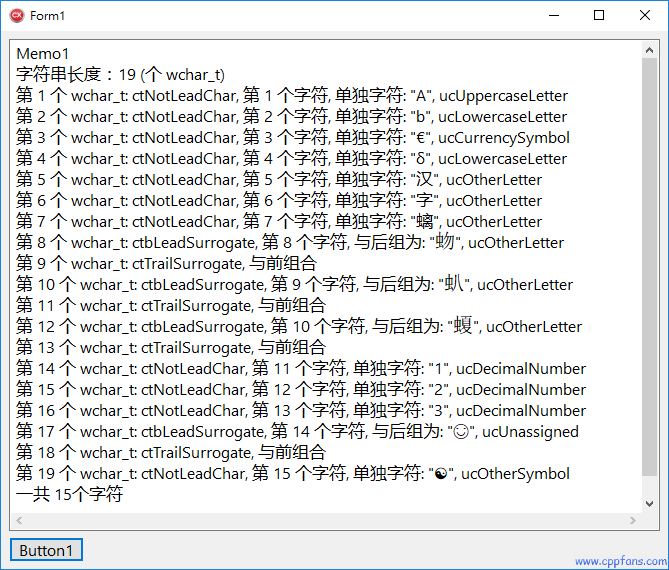
执行结果分析:
(1) 字符串长度 19,一共 15 个字符,“𧉚𧈢𧏡” 这三个汉字和 “😊” 这个表情符号是代理对,即 2 个 char16_t 组合成的 4 字节的字符,是在 UNICODE 辅助平面里面的字符,其他的字符都是单个 char16_t 的。
由于很多软件和网站代码都不支持代理对,或者无法正确处理代理对,所以无法支持 UNICODE 辅助平面里面的字符,螭𧉚和𧈢𧏡常误写为螭吻和蚣蝮就很容易理解了,由于软件不支持,就用了相近的字代替,这让电脑里面的文章出现很多的错别字。由于辅助平面里面的文字几乎都是不常用的文字,所以多数软件厂家也并不关心代理对和辅助平面。
由于在 UNICODE 6.0 版本开始增加了表情符号 Emoticons/Emoji,例如 “😊”,这些表情符号在辅助平面里面,这反而让很多软件厂家感兴趣,让很多软件支持了代理对和辅助平面字符,所以我们还是应该感谢一下 Emoticons 让很多软件支持了 UNICODE 辅助平面里面不常用的文字。
(2) C++ Builder 里面的 GetUnicodeCategory 函数可以区分不同语言的文字当中的符号,大小写等,例如 “A” 是大写字母,“δ” 是小写字母,“€” 是货币符号,汉字是不区分大小写的字母,BMP 和辅助平面里面的汉字都可以识别,“☯” 是其他符号,而表情符号 “😊” 识别为 ucUnassigned 未定义的分类,这说明,在这个测试程序使用的 C++ Builder 10.1 Berlin 版本,还不支持把表情符号识别为一个字符分类。
|