UnicodeString 简介
UnicodeString: 编码为 UTF-16 的字符串,C++ Builder 里面最常用的字符串类型
UnicodeString 成员
• 属性 • 方法 • 事件 • 类型 • 数据
头文件:
#include <System.hpp>
命名空间:
System
继承关系:
无
例:赋值、数据指针、引用计数的测试
通过这个测试程序:
• 测试赋值及引用计数;
• 理解 “不建议通过 c_str()、w_str() 和 data() 返回的指针修改字符串内容”;
• 测试 Unique 方法的作用。
• 赋值的时候,只是让两个字符串共有同一个数据,把引用计数增加,这样会以最快的速度处理字符串。
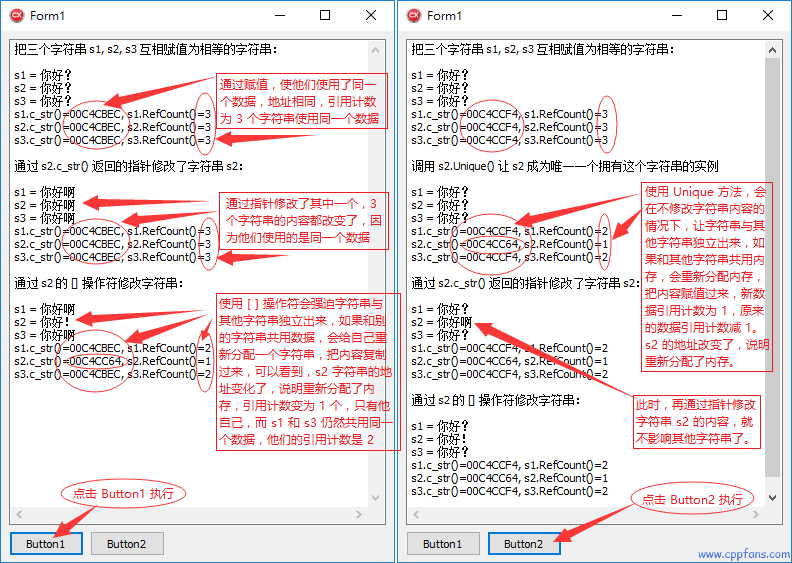
void __fastcall TForm1::Button1Click(TObject *Sender)
{
UnicodeString s1 = L"你好?";
UnicodeString s2 = s1;
UnicodeString s3 = L"Victor";
s3 = s1;
Memo1->Lines->Add(L"把三个字符串 s1, s2, s3 互相赋值为相等的字符串:\r\n");
Memo1->Lines->Add(L"s1 = " + s1);
Memo1->Lines->Add(L"s2 = " + s2);
Memo1->Lines->Add(L"s3 = " + s3);
UnicodeString s;
Memo1->Lines->Add(s.sprintf(L"s1.c_str()=%p, s1.RefCount()=%d", s1.c_str(), s1.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s2.c_str()=%p, s2.RefCount()=%d", s2.c_str(), s2.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s3.c_str()=%p, s3.RefCount()=%d", s3.c_str(), s3.RefCount()));
Memo1->Lines->Add(L"\r\n通过 s2.c_str() 返回的指针修改了字符串 s2:\r\n");
wchar_t *p = s2.c_str();
p[2] = L'啊';
Memo1->Lines->Add(L"s1 = " + s1);
Memo1->Lines->Add(L"s2 = " + s2);
Memo1->Lines->Add(L"s3 = " + s3);
Memo1->Lines->Add(s.sprintf(L"s1.c_str()=%p, s1.RefCount()=%d", s1.c_str(), s1.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s2.c_str()=%p, s2.RefCount()=%d", s2.c_str(), s2.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s3.c_str()=%p, s3.RefCount()=%d", s3.c_str(), s3.RefCount()));
Memo1->Lines->Add(L"\r\n通过 s2 的 [] 操作符修改字符串:\r\n");
s2[3] = L'!';
Memo1->Lines->Add(L"s1 = " + s1);
Memo1->Lines->Add(L"s2 = " + s2);
Memo1->Lines->Add(L"s3 = " + s3);
Memo1->Lines->Add(s.sprintf(L"s1.c_str()=%p, s1.RefCount()=%d", s1.c_str(), s1.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s2.c_str()=%p, s2.RefCount()=%d", s2.c_str(), s2.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s3.c_str()=%p, s3.RefCount()=%d", s3.c_str(), s3.RefCount()));
} |
void __fastcall TForm1::Button2Click(TObject *Sender)
{
UnicodeString s1 = L"你好?";
UnicodeString s2 = s1;
UnicodeString s3 = L"Victor";
s3 = s1;
Memo1->Lines->Add(L"把三个字符串 s1, s2, s3 互相赋值为相等的字符串:\r\n");
UnicodeString s;
Memo1->Lines->Add(L"s1 = " + s1);
Memo1->Lines->Add(L"s2 = " + s2);
Memo1->Lines->Add(L"s3 = " + s3);
Memo1->Lines->Add(s.sprintf(L"s1.c_str()=%p, s1.RefCount()=%d", s1.c_str(), s1.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s2.c_str()=%p, s2.RefCount()=%d", s2.c_str(), s2.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s3.c_str()=%p, s3.RefCount()=%d", s3.c_str(), s3.RefCount()));
Memo1->Lines->Add(L"\r\n调用 s2.Unique() 让 s2 成为唯一一个拥有这个字符串的实例\r\n");
s2.Unique();
Memo1->Lines->Add(L"s1 = " + s1);
Memo1->Lines->Add(L"s2 = " + s2);
Memo1->Lines->Add(L"s3 = " + s3);
Memo1->Lines->Add(s.sprintf(L"s1.c_str()=%p, s1.RefCount()=%d", s1.c_str(), s1.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s2.c_str()=%p, s2.RefCount()=%d", s2.c_str(), s2.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s3.c_str()=%p, s3.RefCount()=%d", s3.c_str(), s3.RefCount()));
Memo1->Lines->Add(L"\r\n通过 s2.c_str() 返回的指针修改了字符串 s2:\r\n");
wchar_t *p = s2.c_str();
p[2] = L'啊';
Memo1->Lines->Add(L"s1 = " + s1);
Memo1->Lines->Add(L"s2 = " + s2);
Memo1->Lines->Add(L"s3 = " + s3);
Memo1->Lines->Add(s.sprintf(L"s1.c_str()=%p, s1.RefCount()=%d", s1.c_str(), s1.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s2.c_str()=%p, s2.RefCount()=%d", s2.c_str(), s2.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s3.c_str()=%p, s3.RefCount()=%d", s3.c_str(), s3.RefCount()));
Memo1->Lines->Add(L"\r\n通过 s2 的 [] 操作符修改字符串:\r\n");
s2[3] = L'!';
Memo1->Lines->Add(L"s1 = " + s1);
Memo1->Lines->Add(L"s2 = " + s2);
Memo1->Lines->Add(L"s3 = " + s3);
Memo1->Lines->Add(s.sprintf(L"s1.c_str()=%p, s1.RefCount()=%d", s1.c_str(), s1.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s2.c_str()=%p, s2.RefCount()=%d", s2.c_str(), s2.RefCount()));
Memo1->Lines->Add(s.sprintf(L"s3.c_str()=%p, s3.RefCount()=%d", s3.c_str(), s3.RefCount()));
}
//--------------------------------------------------------------------------- |
相关链接:
• UnicodeString 编码与编码转换
· 字符类型 - UnicodeCategory
· 字符个数和字节数
· 判断字符串里面的字符是双字节字符或是四字节字符
获取字符串长度、字符个数、每个字符的类型
· 判断字符串里面的字符是汉字或是英文
判断字符串里面的字符是否为汉字,获取汉字的 CJK 分组,计算代理对的 UNICODE 编码值
获取字符串里面汉字的个数和第几个字符是汉字:
获取字符串里面的汉字所在的 CJK 分组
· 编码转换:UTF-8,UTF-16,UTF-32,ANSI,GBK/GB2312,BIG5,……
UnicodeString 和 std::string, std::wstring 之间的转换,让 std::string 支持 UTF-8 或其他编码
· 获取字符串或字符的 ANSI 代码页列表
• 大小写转换
• 分割字符串,利用字符串里面包含的字符或字符串拆分字符串
• 字符串相加,几个字符串连接在一起
• 截取字符串的一部分,把字符串前面或/和后面的空格删掉,把字符串当中的一部分删掉
• 把字符串里面的某个内容替换为另一个内容
• 字符串和整数、浮点数、日期时间之间的转换
· 字符串和整数之间的转换,进位制转换
· 字符串和枚举型之间的转换
· 字符串和浮点数之间的转换,小数点位数、千分位分割、科学计数法
· 字符串和日期时间之间的转换,日期时间的格式
• 格式化输出到字符串
|