AnsiString 简介
C++ Builder 的里面的 AnsiString 是通过 AnsiStringT<0> 定义的:
| typedef AnsiStringT<0> AnsiString; |
所以,AnsiString 就和 AnsiStringT<0> 一模一样的,是 ANSI 本地编码的,代码页为 CP_ACP (0) 的字符串。
继承关系:
AnsiStringBase → AnsiStringT → AnsiString
头文件:
#include <sysmac.h>
AnsiString 成员
编码与编码转换
AnsiString 是 ANSI 本地编码的字符串,代码页为 CP_ACP 即等于 Code Page 0
ANSI 本地编码在不同的国家/地区,使用不同的字符编码:
• 在中国大陆和新加坡,对应于 Code Page 936 代码页,字符编码为 GBK。
• 在中国台湾、香港和澳门,对应于 Code Page 950 代码页,字符编码为 BIG5。
• 在其他国家或地区的代码页和编码,请看 “ANSI 编码” 章节的内容。
由于 AnsiStringT 的存在,让字符编码之间转换变得非常的容易了。
| UNICODE (UTF-16) 和 ANSI 之间字符编码转换是自动的 |
UnicodeString u;
AnsiString s;
s = u; // UNICODE (UTF-16) 转 ANSI
u = s; // ANSI 转 UNICODE (UTF-16) |
| UTF-8 和 ANSI 之间字符编码转换是自动的 |
UTF8String u;
AnsiString s;
s = u; // UTF-8 转 ANSI
u = s; // ANSI 转 UTF-8 |
| GBK, GB2312, BIG5 和 ANSI 之间字符编码也可以自动转换 |
AnsiStringT<936> gbk; // 大陆和新加坡简体中文和繁体中文都有
AnsiStringT<950> big5; // 港澳台的 BIG5 只有繁体中文
AnsiStringT<20936> gb2312; // 大陆的早期编码 GB2312 只有简体中文
AnsiString s; // 以上字符串之间可以随意互相赋值进行自动转码
s = gbk;
gbk = big5;
big5 = CHS2CHT(gb2312); // GB2312 和 BIG5 之间需要简体中文和繁体中文之间转换
…… |
更多字符编码转换的例子,可以参考 “字符编码之间转换” 章节的内容。
字节类型,字符个数和字节数 - 判断字符串里面的字符是双字节字符或是单字节字符,还有四字节字符的判断
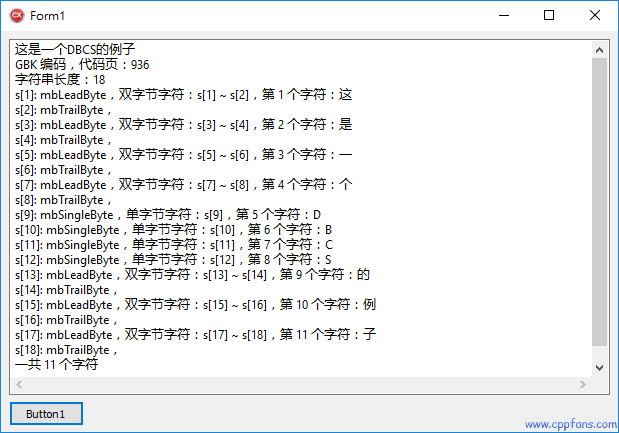
例1:双字节字符集 (DBCS) 的例子 - GBK 编码的例子
双字节字符集 DBCS,大陆 GBK 编码 (代码页 936) 的例子,台湾和香港地区的 BIG5 编码 (代码页 950) 将会得到同样的结果。
相关链接:ANSI • DBCS • MBCS • GBK • GB18030 • 代码页 CP 936 • EnumToStr
void __fastcall TForm1::Button1Click(TObject *Sender)
{
AnsiString s = L"这是一个DBCS的例子"; // 中国大陆 GBK 编码,代码页 936
Memo1->Lines->Add(s);
Memo1->Lines->Add(_T("GBK 编码,代码页:936"));
int n = s.Length();
Memo1->Lines->Add(_T("字符串长度:") + IntToStr(n));
int iCharCount = 0; // 字符个数
for(int i=1; i<=n; i++)
{
AnsiString::TStringMbcsByteType bt = s.ByteType(i);
String sInfo;
sInfo.sprintf(L"s[%d]: ", i);
sInfo += EnumToStr(bt) + L",";
switch(bt)
{
case AnsiString::mbSingleByte:
sInfo.cat_sprintf(_T("单字节字符:s[%d],第 %d 个字符:"), i, ++iCharCount);
sInfo += s.SubString(i,1);
break;
case AnsiString::mbLeadByte :
sInfo.cat_sprintf(_T("双字节字符:s[%d] ~ s[%d],第 %d 个字符:"), i, i+1, ++iCharCount);
sInfo += s.SubString(i,2);
break;
case AnsiString::mbTrailByte :
break;
}
Memo1->Lines->Add(sInfo);
}
Memo1->Lines->Add(_T("一共 ") + IntToStr(iCharCount) + _T(" 个字符"));
}
|
运行结果:
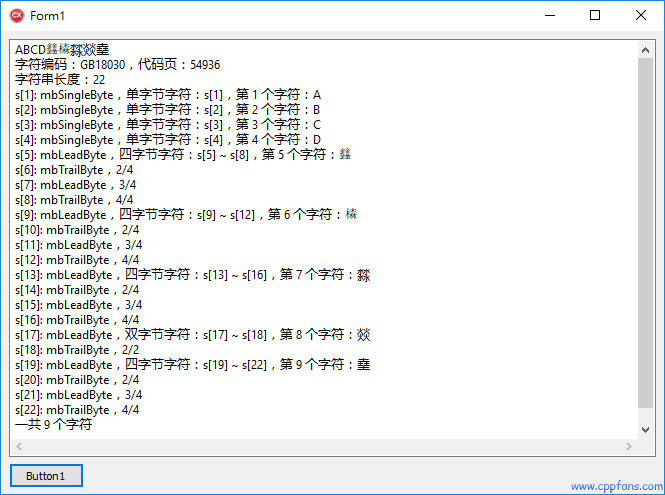
例2:多字节字符集 (MBCS) 的例子 - GB18030 编码的例子
相关链接:ANSI • DBCS • MBCS • GBK • GB18030 • 代码页 CP 936 • EnumToStr
void __fastcall TForm1::Button1Click(TObject *Sender)
{
AnsiStringT<54936>s = L"ABCD𨰻𣛧㵘燚㙓"; // GB18030
Memo1->Lines->Add(s);
Memo1->Lines->Add(_T("字符编码:GB18030,代码页:54936"));
int n = s.Length();
Memo1->Lines->Add(L"字符串长度:" + IntToStr(n));
int iCharCount = 0;
int i4bytes = 0;
for(int i=1; i<=n; i++)
{
AnsiString::TStringMbcsByteType bt = s.ByteType(i);
String sInfo;
sInfo.sprintf(_T("s[%d]: "),i);
sInfo += EnumToStr(bt) + L",";
switch(bt)
{
case AnsiString::mbSingleByte:
iCharCount++;
sInfo.cat_sprintf(_T("单字节字符:s[%d],第 %d 个字符:"), i, iCharCount);
sInfo += s.SubString(i,1);
break;
case AnsiString::mbLeadByte:
if(i4bytes)
{
sInfo.cat_sprintf(_T("%d/4"), ++i4bytes);
}
else if(s[i+1]>=0x30 && s[i+1]<=0x39) // 下一个字节 s[i+1] 的取值范围确定了是四字节字符
{
i4bytes++;
iCharCount++;
sInfo.cat_sprintf(_T("四字节字符:s[%d] ~ s[%d],第 %d 个字符:"), i, i+3, iCharCount);
sInfo += s.SubString(i,4);
}
else
{
iCharCount++;
sInfo.cat_sprintf(_T("双字节字符:s[%d] ~ s[%d],第 %d 个字符:"), i, i+1, iCharCount);
sInfo += s.SubString(i,2);
}
break;
case AnsiString::mbTrailByte:
if(i4bytes)
{
sInfo.cat_sprintf(_T("%d/4"), ++i4bytes);
if(i4bytes==4)i4bytes=0;
}
else
{
sInfo += _T("2/2");
}
break;
}
Memo1->Lines->Add(sInfo);
}
Memo1->Lines->Add(_T("一共 ") + IntToStr(iCharCount) + _T(" 个字符"));
} |
运行结果:
判断字符串里面的字符是汉字或是英文
判断英文很简单,只要字节类型是单字节字符,并且范围在 'A' ~ 'Z' 或 'a' ~ 'z' 之间,就是英文。
判断汉字就比较复杂了,如果是 UNICODE 编码,只要判断是 CJK 中日韩统一文字就可以了,
ANSI 编码没有统一的判断方法,要看具体的编码,比如 GBK 编码、GB18030 编码,或者 BIG5 编码。
现在的 C++ Builder 版本,字符串都是 UnicodeString 类型的了,这里是 UnicodeString 的相关链接:
 判断字符串里面的字符是汉字或是英文 判断字符串里面的字符是汉字或是英文
判断字符串里面的字符是否为汉字,获取汉字的 CJK 分组,计算代理对的 UNICODE 编码值
获取字符串里面汉字的个数和第几个字符是汉字:
获取字符串里面的汉字所在的 CJK 分组
只有早期版本的 C++ Builder 才需要判断 ANSI 编码的汉字或英文字符。
大小写转换
现在的 C++ Builder 版本,字符串都是 UnicodeString 类型的了,这里是 UnicodeString 的相关链接:
大小写转换
只有早期版本的 C++ Builder 才需要处理 ANSI 编码的大小写。
字符串相加,几个字符串连接在一起
现在的 C++ Builder 版本,字符串都是 UnicodeString 类型的了,这里是 UnicodeString 的相关链接:
字符串相加,几个字符串连接在一起
UnicodeString 可以和 AnsiString、UTF8String、AnsiStringT 进行相加,会连接到一起
只有早期版本的 C++ Builder 才需要处理 ANSI 编码的字符串。
其他字符串操作请参考 UnicodeString
现在的 C++ Builder 版本,字符串都是 UnicodeString 类型的了,这里是 UnicodeString 的相关链接:
判断字符串里面的字符是汉字或是英文
· 判断字符串里面的字符是否为汉字,获取汉字的 CJK 分组,计算代理对的 UNICODE 编码值
· 获取字符串里面汉字的个数和第几个字符是汉字:
· 获取字符串里面的汉字所在的 CJK 分组
· 获取字符串或字符的 ANSI 代码页列表
大小写转换
分割字符串,利用字符串里面包含的字符或字符串拆分字符串
字符串相加,几个字符串连接在一起
· UnicodeString 可以和 AnsiString、UTF8String、AnsiStringT 进行相加,会连接到一起
截取字符串的一部分,把字符串前面或/和后面的空格删掉,把字符串当中的一部分删掉
把字符串里面的某个内容替换为另一个内容
字符串和整数、浮点数、日期时间之间的转换
· 字符串和整数之间的转换,进位制转换
· 字符串和枚举型之间的转换
· 字符串和浮点数之间的转换,小数点位数、千分位分割、科学计数法
· 字符串和日期时间之间的转换,日期时间的格式
格式化输出到字符串
|