一把梭系列 ~ C語言範例 (0012) [字元陣列與字串]
一把梭系列 ~ C語言範例 (0012) [字元陣列與字串]
資料來源: https://openhome.cc/Gossip/CGossip/String.html
https://www.twblogs.net/a/5cbaed6bbd9eee0eff45fff0
https://www.itread01.com/content/1543744384.html
https://www.ibm.com/docs/SSLTBW_2.2.0/com.ibm.zos.v2r2.bpxbd00/fgetwsp.htm
★前言:

★主題:
字串就是一串文字,在 C 談到字串的話,一個意義是指字元組成的陣列,最後加上一個空(null)字元 ‘\0’,例如底下是個 “hello” 字串:
char text[] = {'h', 'e', 'l', 'l', 'o', '\0'};
之後可以直接使用 text 來代表 “hello” 文字,例如:
printf("%s\n", text);
也可以使用 “” 來包含文字,例如:
char text[] = "hello";
“hello” 是字串字面常量,在這個例子中,雖然沒有指定空字元 ‘\0’,但是會自動加上空字元。
字串是字元陣列,可以用陣列存取方式取出每個字元,在指定 “hello” 時表面上雖然只有 5 個字元, 但是最後會加上一個空字元 ‘\0’,因此 text 就陣列長度而言會是 6,不過就字串長度而言會是 5,strlen 可以取得字串長度,定義在 string.h。
由使用者輸入取得字串值時,需注意不要超過字串(字元陣列)的長度;使用 scanf 從使用者輸入取得字串值,並儲存至字元陣列,只要這麼作就可以了:
char buf[80];
printf("輸入字串:");
scanf("%s", buf);
printf("你輸入的字串為 %s\n", buf);
這個程式片段可以取得使用者的字串輸入,輸入的字串長度不得超過 80 個字元,80 個字元的上限包括空字元,因此實際上可以輸入 79 個字元;如果輸入的字元超出所宣告的上限,會發生不可預期的結果,甚至成為安全弱點,如〈printf 與 scanf〉中最後談到的,預防的方法之一是,限定 scanf 每次執行可以接受的最大字元數,或者是使用 fgets。
在使用 scanf 取得使用者輸入的字串時,格式指定字是使用 %s,而變數前不用再加上 &,因為實際上,字串(字元陣列)變數名稱本身,即表示記憶體位址資訊。
當字串內容不只有單純的英文和數字時,此時『編譯器設定(整合開發環境 IDE)』和 程式碼內『字串變數宣告型態』就會影想 輸出結果
例如:
文字「林」不會是一個位元組就可以儲存的資料,因此引發警訊,你需要使用以下的方式:
char text[] = "林";
若使用 strlen(text) 的話,會得到什麼數字呢?若單純使用 gcc 編譯,不加上任何引數的話,答案是看你的原始碼編碼是什麼,如果使用 Big5 撰寫原始碼的話,答案會是 2,如果使用 UTF-8 撰寫原始碼的話,答案會是 3。
現代程式設計鼓勵使用 UTF-8,如果使用 UTF-8 撰寫原始碼,單純使用 gcc 編譯,不加上任何引數的話,若是在 Windows 的文字模式執行程式,就會出現亂碼,因為 Windows 的文字模式預設採用 Big5(MS950),為了可以看到正確的文字,編譯時可以加上 -fexec-charset=BIG5,執行時期字串使用 Big5 編碼,這時 strlen(text) 又會是 2 了。
這就要問到一個問題了,字元是什麼呢?C 的 char 又是什麼呢?C 是個歷史悠久的語言,早期用 char 儲存的文字僅需單一位元組,例如 ASCII 的文字,使用 char 代表字元是沒問題,因為 ASCII 既定義了字元集,也定義了字元編碼,在表示 ASCII 的文字時,char 確實就代表字元,然而後來為了支援更多的文字,char 就不再是代表字元了。
char 是用來儲存字元資料,至於存什麼沒有規定,對於 char text[] = “林” 的情況,應該將 text 中每個索引位置當成是碼元(code unit),而不是字元了,因為必須以多個位元組來儲存「林」,因此這類字元在 C 被稱為多位元組字元(multibyte character),技術上來說,是用數個 char 組成的一個字元,如何組成就要看採用哪種編碼了。
如果採用 Big5 編碼,那 “林” 是個 Big5 字元,如果採用 UTF-8 編碼,那 “林” 是個 Unicode 字元,現代程式設計鼓勵用 UTF-8,所以在此建議如果要存取非英數字的字串就用專屬的資料型態 wchar_t。
★code:
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
#include <locale.h>
#include <string.h>
int main()
{
//*
int i;
char text[] = "hello";
int length = sizeof(text) / sizeof(text[0]);
for(i = 0; i < length; i++) {
if(text[i] == '\0') {
puts("null");
} else {
printf("%c ", text[i]);
}
}
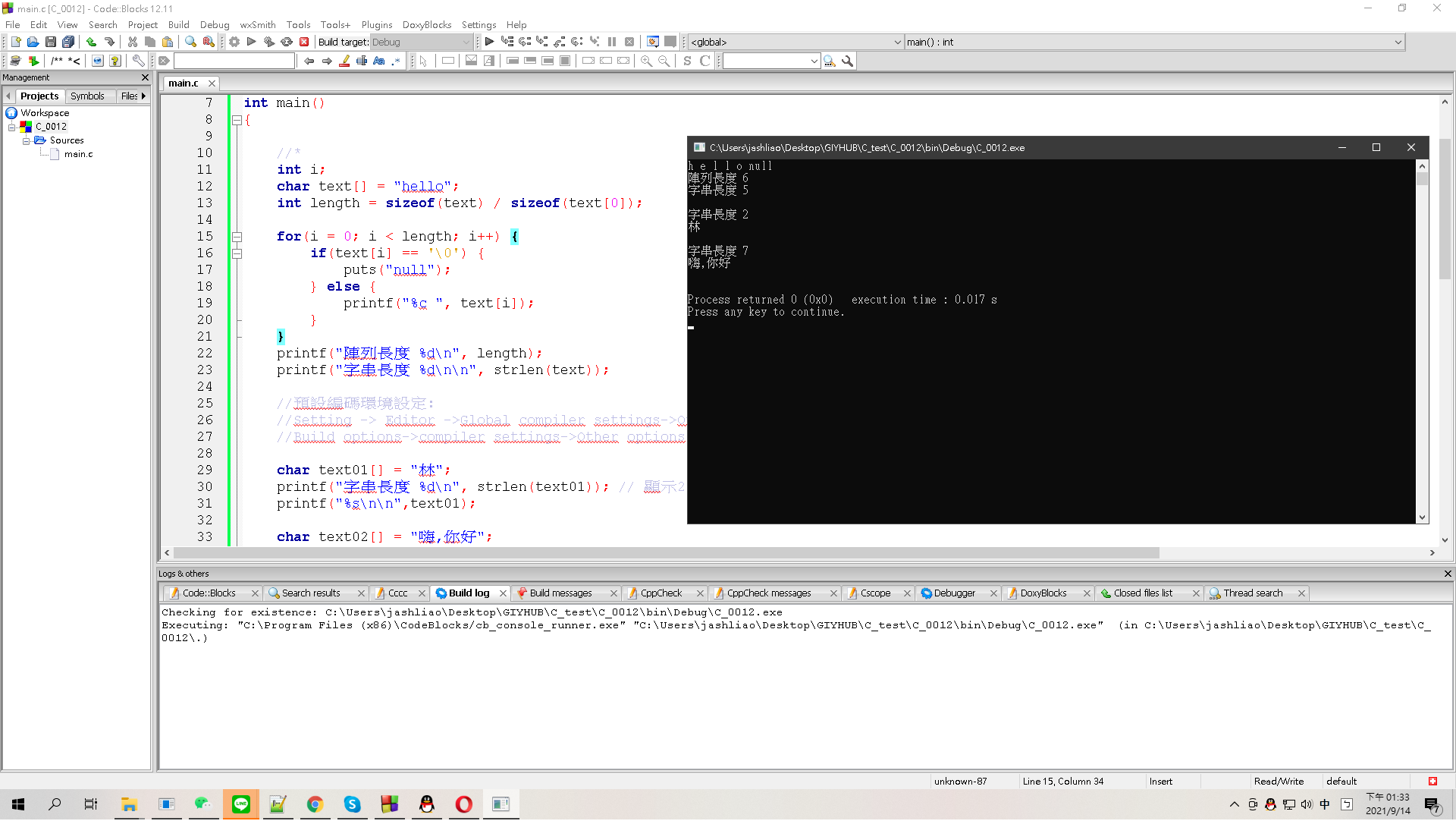
printf("陣列長度 %d\n", length);
printf("字串長度 %d\n\n", strlen(text));
//預設編碼環境設定:
//Setting -> Editor ->Global compiler settings->Other options -> default
//Build options->compiler settings->Other options []
char text01[] = "林";
printf("字串長度 %d\n", strlen(text01)); // 顯示2
printf("%s\n\n",text01);
char text02[] = "嗨,你好";
printf("字串長度 %d\n", strlen(text02)); // 顯示7
printf("%s\n\n",text02);
//*/
/*
//使用寬字串/UTF-8 環境設定:
//Setting -> Editor ->Global compiler settings->Other options -> UTF-8
//Build options->compiler settings->Other options [-finput-charset=UTF-8]
setlocale(LC_ALL, "");
wchar_t text03[] = L"\u6797";
wprintf(L"字串長度 %d\n", strlen(text03));
wprintf(L"寬字串長度 %d\n", wcslen(text03)); // 顯示 1
printf("%ls\n\n",text03);
wchar_t text04[10] = { 0x55E8, 0x3001, 0x4F60, 0x597D};
wprintf(L"字串長度 %d\n", strlen(text04));
wprintf(L"寬字串長度 %d\n", wcslen(text04)); // 顯示 4
wprintf(L"%s\n\n",text04);
wchar_t text05[10]=L"嗨,你好";
wprintf(L"字串長度 %d\n", strlen(text05));
wprintf(L"寬字串長度 %d\n", wcslen(text05)); // 顯示 4
printf("%ls\n",text05);
wprintf(L"%s\n\n",text05);
wchar_t* x = L"Food\n嗨,你好\n";
FILE* outFile00 = fopen( "Serialize.txt", "w+,ccs=UTF-8");//具有BOM UTF-8 FILE
fwrite(x, wcslen(x) * sizeof(wchar_t), 1, outFile00);
fwprintf(outFile00, L"%s", x);//fwprintf(outFile00, L"%hs", x);
fclose(outFile00);
FILE *file=fopen("Serialize.txt", "r,ccs=UTF-8");
wchar_t buffer[513], ch=1;
wprintf(L"Serialize.txt:\n");
while(fgetws(buffer,512,file) != NULL)
{
wprintf(L"%s",buffer);
}
fclose(file);
//*/
return 0;
}
★結果:
★延伸說明/重點回顧:
01.C語言的字串就是字元陣列
02.如果不指定字串編碼格式,則編譯器會使用系統預設(PS並非UTF-8)
03.如果當字串內會有非英數字的內容,建議將編譯器設定為UTF-8編譯模式,並且使用wchar_t資料型態
04.本篇最後一段範例實作的UTF-8純文字檔的讀/寫功能,這一部分純粹是隱藏彩蛋,不用目前學會
One thought on “一把梭系列 ~ C語言範例 (0012) [字元陣列與字串]”
C/C++
UTF8/BIG5
string (字串)/ FILE (檔案)
READ/WRITE (讀/寫) 一行一行
char/wchar_t
陣列 (Array)
-fexec-charset=BIG5
-finput-charset=UTF-8