機器學習 & 人工智慧(深度學習) & 大數據分析 完整實際步驟 收藏
機器學習 & 人工智慧(深度學習) & 大數據分析 完整實際步驟 收藏
資料來源: https://mp.weixin.qq.com/s/D62NWBn-lFoXpRlvdecyNQ
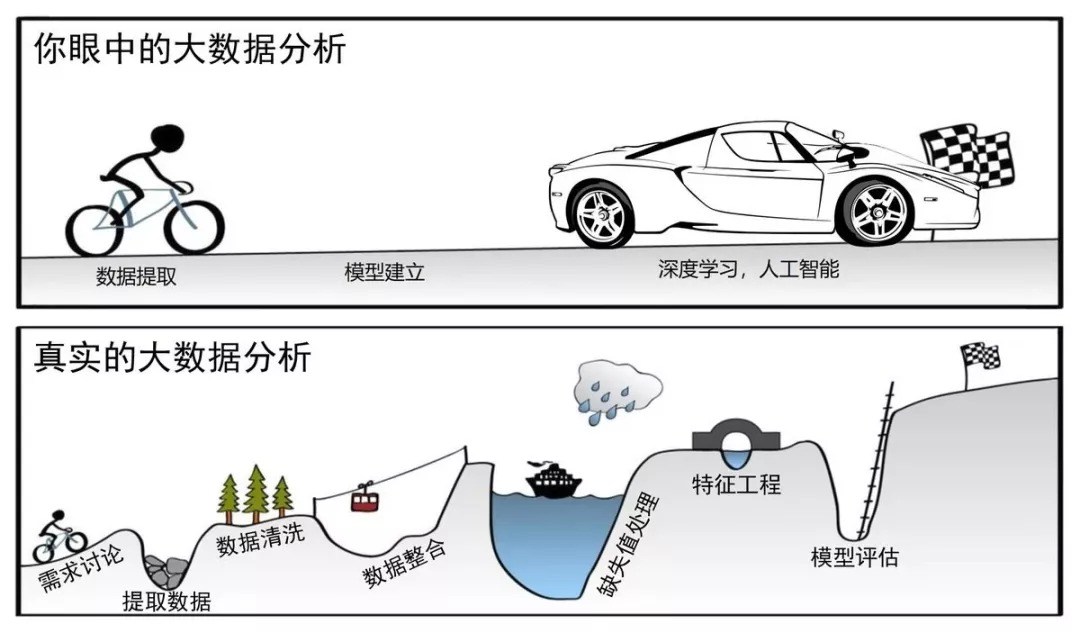
需求討論 -> 抓取(提取)數據 -> 數據清洗過濾 -> 數據整合(合併) -> 缺失處理 -> 特徵(提取)工程 -> 模型(選取)建立
機器學習模型訓練全流程教學 [細部完整流程圖]
其中:
01.【 數據清洗過濾 -> 數據整合(合併) -> 缺失處理 -> 特徵(提取)工程 】 一般都是 統計/經驗 手段取得
02.特徵提取 前要執行 降維 動作
03. 李航《统计学习方法》 、《Python數據分析與挖掘實戰》、實用機器學習 <REAL-WORLD MACHINE LEARNING>、数据科学入门 有上述所有步驟對應理論 + PYTHON實作
//—————————–//
書本範例~模型選擇對應整理:
▲線性回歸 [ https://bit.ly/3cwRdjx ]
從一個地方移動到另一個地方所需的時間
預測下個月某種產品的銷售情況
血液中的酒精含量對協調能力的影響
預測每個月禮品卡的銷售情況,並改善年收入的估算
▲Logistic 回歸 [ https://bit.ly/3cwRdjx ]
預測客戶流失
信用評分和欺詐檢測
評價市場營銷活動的效果
▲貝式分類(Bayes)
男/女分類
特徵: 身高、體重、腳掌長度
郵件分類
情感分析和文本分類
類似於Netflix、Amazon 這樣的推薦系統
人臉識別
▲K-NN
試紙好壞分類
特徵: 耐酸度、強度
手寫數字分類
▲向量機SVM
花草植物分類
特徵: 花萼長度、花萼寬度、花瓣寬度、花瓣長度
行人偵測
發現患有糖尿病等常見疾病的人
手寫字符識別
文本分類——將文章按照話題分類
股票市場價格預測
▲決策樹
信用貸款
特徵: 年紀、薪水、房屋、車、信用[每一種都分等級]
醫療判斷
做出投資決策
預測客戶流失
找出可能拖欠銀行貸款的人
在「建造」和「購買」兩種選擇間進行抉擇
銷售主管的資質審核
▲AdaBoost
座標分類
▲梯度提升樹
同區房屋估價
特徵: 面積、房間數
▲隨機森林
同區房屋估價
特徵: 面積、房間數
預測高危患者
預測零件在生產中的故障
預測拖欠貸款的人
▲神經網路
花草植物分類
特徵: 花萼長度、花萼寬度、花瓣寬度、花瓣長度
行人偵測
//—————————–//
主要分類與預測算法 運用 場合 介紹 [Python數據分析與挖掘實戰 P84、103]
回归分析:
01.比较基础的线性分类模型,很多时候是简单有效的选择
02.确定预测属性(数值型)与其他变量间相互依赖的定量关系最常用的统计学方法。包括线性回归、非线性回归、Logistic回归、岭回归、主成分回归、偏最小二乘回 回归分析归等模型
决策树:
01.基于“分类讨论、逐步细化”思想的分类模型,模型直观,易解释,如 前面5.1.4节中可以直接给出决策图
02.采用自顶向下的递归方式,在内部节点进行属性值的比较,并根据不同的属性值决策树从该节点向下分支,最终得到的叶节点是学习划分的类
人工神经网络:
01.具有强大的拟合能力,可以用于拟合、分类等,它有很多个增强版本,如递神经网络、卷积神经网络、自编码器等,这些是深度学习的模型基础
02.一种模仿大脑神经网络结构和功能而建立的信息处理系统,表示神经网人工神经网络络的输入与输出变量之间关系的模型
贝叶斯网络:
01.基于概率思想的简单有效的分类模型,能够给出容易理解的概率解释
02.又称信度网络,是Bayes方法的扩展,是目前不确定知识表达和推理领域最贝叶斯网络有效的理论模型之一
支持向量机:
01.强大的模型,可以用来回归、预测、分类等,而根据选取不同的核函数。模型可以是线性的/非线性的
02.一种通过某种非线性映射,把低维的非线性可分转化为高维的线性可分,支持向量机在高维空间进行线性分析的算法
~~~~~~~~~~~~~~~~~~
回歸分析:
01.比較基礎的線性分類模型,很多時候是簡單有效的選擇
02.確定預測屬性(數值型)與其他變量間相互依賴的定量關係最常用的統計學方法。包括線性回歸、非線性回歸、Logistic回歸、嶺回歸、主成分回歸、偏最小二乘回 回歸分析歸等模型
決策樹:
01.基於“分類討論、逐步細化”思想的分類模型,模型直觀,易解釋,如 前面5.1.4節中可以直接給出決策圖
02.採用自頂向下的遞歸方式,在內部節點進行屬性值的比較,並根據不同的屬性值決策樹從該節點向下分支,最終得到的葉節點是學習劃分的類
人工神經網絡:
01.具有強大的擬合能力,可以用於擬合、分類等,它有很多個增強版本,如遞神經網絡、卷積神經網絡、自編碼器等,這些是深度學習的模型基礎
02.一種模仿大腦神經網絡結構和功能而建立的信息處理系統,表示神經網人工神經網絡絡的輸入與輸出變量之間關係的模型
貝葉斯網絡(貝式分類):
01.基於概率思想的簡單有效的分類模型,能夠給出容易理解的概率解釋
02.又稱信度網絡,是Bayes方法的擴展,是目前不確定知識表達和推理領域最貝葉斯網絡有效的理論模型之一
支持向量機:
01.強大的模型,可以用來回歸、預測、分類等,而根據選取不同的核函數。模型可以是線性的/非線性的
02.是一種通過某種非線性映射,把低維的非線性可分轉化為高維的線性可分,支持向量機在高維空間進行線性分析的算法
//—————————–//
演算法評價 [Python數據分析與挖掘實戰 P100~102]
絕對誤差
E=Y-Y’
相對誤差
E=(Y-Y’)/Y
E=(Y-Y’)/Y*100%
平均絕對誤差
MAE=1/n * Σ(Y-Y’)
均方誤差
MSE=1/n * Σ((Y-Y’)*(Y-Y’))
均方根誤差
RMSE=√( 1/n * Σ((Y-Y’)*(Y-Y’)) )
平均絕對百分比誤差
MAPE=1/n * Σ|(Y-Y’)/Y|
辨識準確度
Accuracy=(TP+FP)/(TP+TN+FP+FN)
識別精確度
Precision=TP/(TP+FP)*100%
反饋率
Recall=TP/(TP+TN)
其中
Y:期望值/目標值
Y’:估測值/運算結果
TP (True Positives):正確的肯定表示正確肯定的分類數。
TN (True Negatives):正確的否定表示正確否定的分類數。
FP (False Positives):錯誤的肯定表示錯誤肯定的分類數。
FN (False Negatives):錯誤的否定表示錯誤否定的分類數。
//—————————–//
心得:
01.模型選擇都先比對和書本類似的先測試
02.如果上述效果很差,就使用OPEN CV 依序測試找尋最佳解 又或者 直接使用神經網路硬幹
5 thoughts on “機器學習 & 人工智慧(深度學習) & 大數據分析 完整實際步驟 收藏”
機器學習 流程 步驟
機器學習 流程 分析 步驟
https://kknews.cc/zh-tw/code/6evg5vv.html
01.數據提取
02.數據清洗
03.數據整合
04.損失處理
05.特徵提取
06.模型選擇
特徵提取 前要執行 降維 動作
[ 12种降维方法终极指南(含Python代码)]
https://zhuanlan.zhihu.com/p/43225794
1. 缺失值比率(Missing Value Ratio)
2. 低方差濾波(Low Variance Filter)
3. 高相關濾波(High Correlation filter)
4. 隨機森林(Random Forest)
5. 反向特徵消除(Backward Feature Elimination)
6. 前向特徵選擇(Forward Feature Selection)
7. 因子分析(Factor Analysis)
8. 主成分分析(PCA)
9. 獨立分量分析(ICA)
10. IOSMAP
11. t-SNE
12. UMAP
機器學習 & 人工智慧(深度學習) & 大數據分析 完整實際步驟 SOP 收藏
機器學習 & 人工智慧(深度學習) & 大數據分析 的10大算法應用場景建議 SOP
https://mp.weixin.qq.com/s/d4dL_MS0DtjZNQOaeZ_ovA
01.線性回歸:
線性回歸(Linear Regression )可能是最流行的機器學習算法。線性回歸就是要找一條直線,並且讓這條直線盡可能地擬合散點圖中的數據點。它試圖通過將直線方程與該數據擬合來表示自變量(x 值)和數值結果(y 值)。然後就可以用這條線來預測未來的值!
這種算法最常用的技術是最小二乘法(Least of squares)。這個方法計算出最佳擬合線,以使得與直線上每個數據點的垂直距離最小。總距離是所有數據點的垂直距離(綠線)的平方和。其思想是通過最小化這個平方誤差或距離來擬合模型。
比如預測明年的房價漲幅、下一季度新產品的銷量等等。聽起來並不難,不過線性回歸算法的難點並不在於得出預測值,而在於如何更精確。為了那個可能十分細微的數字,多少工程師為之耗盡了青春和頭髮。
02.邏輯回歸:
邏輯回歸(Logistic regression)與線性回歸類似,但邏輯回歸的結果只能有兩個的值。如果說線性回歸是在預測一個開放的數值,那邏輯回歸更像是做一道是或不是的判斷題。
邏輯函數中Y值的範圍從0 到1 ,是一個概率值。邏輯函數通常呈S 型,曲線把圖表分成兩塊區域,因此適合用於分類任務。
比如上面的邏輯回歸曲線圖,顯示了通過考試的概率與學習時間的關係,可以用來預測是否可以通過考試。
邏輯回歸經常被電商或者外賣平台用來預測用戶對品類的購買偏好。
03.決策樹:
如果說線性和邏輯回歸都是把任務在一個回合內結束,那麼決策樹(Decision Trees)就是一個多步走的動作,它同樣用於回歸和分類任務中,不過場景通常更複雜且具體。
舉個簡單例子,老師面對一個班級的學生,哪些是好學生?如果簡單判斷考試90分就算好學生好像太粗暴了,不能唯分數論。那面對成績不到90分的學生,我們可以從作業、出勤、提問等幾個方面分開討論。
以上就是一個決策樹的圖例,其中每一個有分叉的圈稱為節點。在每個節點上,我們根據可用的特徵詢問有關數據的問題。左右分支代表可能的答案。最終節點(即葉節點)對應於一個預測值。
每個特徵的重要性是通過自頂向下方法確定的。節點越高,其屬性就越重要。比如在上面例子中的老師就認為出勤率比做作業重要,所以出勤率的節點就更高,當然分數的節點更高。
04.樸素貝葉斯:(貝式分類)
樸素貝葉斯(Naive Bayes)是基於貝葉斯定理,即兩個條件關係之間。它測量每個類的概率,每個類的條件概率給出x 的值。這個算法用於分類問題,得到一個二進制“是/ 非”的結果。看看下面的方程式。
樸素貝葉斯分類器是一種流行的統計技術,經典應用是過濾垃圾郵件。
當然,學堂君賭一頓火鍋,80%的人沒看懂上面這段話。(80%這個數字是學堂君猜的,但經驗直覺就是一種貝葉斯式的計算。)
用非術語解釋貝葉斯定理,就是通過A條件下發生B的概率,去得出B條件下發生A的概率。比如說,小貓喜歡你,有a%可能性在你面前翻肚皮,請問小貓在你面前翻肚皮,有多少概率喜歡你?
當然,這樣做題,等於抓瞎,所以我們還需要引入其他數據,比如小貓喜歡你,有b%可能和你貼貼,有c%概率發出呼嚕聲。所以我們如何知道小貓有多大概率喜歡自己呢,通過貝葉斯定理就可以從翻肚皮,貼貼和呼嚕的概率中計算出來。
05.支持向量機
支持向量機(Support Vector Machine,SVM)是一種用於分類問題的監督算法。支持向量機試圖在數據點之間繪製兩條線,它們之間的邊距最大。為此,我們將數據項繪製為n 維空間中的點,其中,n 是輸入特徵的數量。在此基礎上,支持向量機找到一個最優邊界,稱為超平面(Hyperplane),它通過類標籤將可能的輸出進行最佳分離。
超平面與最近的類點之間的距離稱為邊距。最優超平面具有最大的邊界,可以對點進行分類,從而使最近的數據點與這兩個類之間的距離最大化。
所以支持向量機想要解決的問題也就是如何把一堆數據做出區隔,它的主要應用場景有字符識別、面部識別、文本分類等各種識別。
06.K-最近鄰算法(KNN)
K- 最近鄰算法(K-Nearest Neighbors,KNN)非常簡單。KNN 通過在整個訓練集中搜索K 個最相似的實例,即K 個鄰居,並為所有這些K 個實例分配一個公共輸出變量,來對對象進行分類。
K 的選擇很關鍵:較小的值可能會得到大量的噪聲和不准確的結果,而較大的值是不可行的。它最常用於分類,但也適用於回歸問題。
用於評估實例之間相似性的距離可以是歐幾里得距離(Euclidean distance)、曼哈頓距離(Manhattan distance)或明氏距離(Minkowski distance)。歐幾里得距離是兩點之間的普通直線距離。它實際上是點坐標之差平方和的平方根。
07.K-均值
K-均值(K-means)是通過對數據集進行分類來聚類的。例如,這個算法可用於根據購買歷史將用戶分組。它在數據集中找到K 個聚類。K- 均值用於無監督學習,因此,我們只需使用訓練數據X,以及我們想要識別的聚類數量K。
該算法根據每個數據點的特徵,將每個數據點迭代地分配給K 個組中的一個組。它為每個K-聚類(稱為質心)選擇K 個點。基於相似度,將新的數據點添加到具有最近質心的聚類中。這個過程一直持續到質心停止變化為止。
生活中,K-均值在欺詐檢測中扮演了重要角色,在汽車、醫療保險和保險欺詐檢測領域中廣泛應用。
08.隨機森林
隨機森林(Random Forest)是一種非常流行的集成機器學習算法。這個算法的基本思想是,許多人的意見要比個人的意見更準確。在隨機森林中,我們使用決策樹集成(參見決策樹)。
(a)在訓練過程中,每個決策樹都是基於訓練集的引導樣本來構建的。
(b)在分類過程中,輸入實例的決定是根據多數投票做出的。
隨機森林擁有廣泛的應用前景,從市場營銷到醫療保健保險,既可以用來做市場營銷模擬的建模,統計客戶來源、保留及流失,也可以用來預測疾病的風險和病患者的易感性。
09.降維
由於我們今天能夠捕獲的數據量之大,機器學習問題變得更加複雜。這就意味著訓練極其緩慢,而且很難找到一個好的解決方案。這一問題,通常被稱為“維數災難”(Curse of dimensionality)。
降維(Dimensionality reduction)試圖在不丟失最重要信息的情況下,通過將特定的特徵組合成更高層次的特徵來解決這個問題。主成分分析(Principal Component Analysis,PCA)是最流行的降維技術。
主成分分析通過將數據集壓縮到低維線或超平面/ 子空間來降低數據集的維數。這盡可能地保留了原始數據的顯著特徵。
可以通過將所有數據點近似到一條直線來實現降維的示例。
10.人工神經網絡(ANN)
人工神經網絡(Artificial Neural Networks,ANN)可以處理大型複雜的機器學習任務。神經網絡本質上是一組帶有權值的邊和節點組成的相互連接的層,稱為神經元。在輸入層和輸出層之間,我們可以插入多個隱藏層。人工神經網絡使用了兩個隱藏層。除此之外,還需要處理深度學習。
人工神經網絡的工作原理與大腦的結構類似。一組神經元被賦予一個隨機權重,以確定神經元如何處理輸入數據。通過對輸入數據訓練神經網絡來學習輸入和輸出之間的關係。在訓練階段,系統可以訪問正確的答案。
如果網絡不能準確識別輸入,系統就會調整權重。經過充分的訓練後,它將始終如一地識別出正確的模式。
每個圓形節點表示一個人工神經元,箭頭表示從一個人工神經元的輸出到另一個人工神經元的輸入的連接。
圖像識別,就是神經網絡中的一個著名應用。
現在,你已經了解了最流行的人工智能算法的基礎介紹,並且,對它們的實際應用也有了一定認識。