一把梭系列 ~ C語言範例 (0015) [字串的掃描與格式化]
一把梭系列 ~ C語言範例 (0015) [字串的掃描與格式化]
資料來源: https://openhome.cc/Gossip/CGossip/SscanfSnprintf.html
http://www.cplusplus.com/reference/cwchar/swscanf/
https://www.cplusplus.com/reference/cwchar/swprintf/
線上執行: https://www.tutorialspoint.com/compile_c_online.php [不想/不能 安裝開發工具 非寬字串替代方案]
★前言:

★主題:
但由於它就具有各元素依序組合後的實際單詞義意,並且也依照不同編碼格式而有所不同,因此C語言有提供一系列的對應函數方便使用者使用。
下面我們就將C語言提供的相關功能進行分門別類的初步整理與介紹:
01.字串的分析掃描 切割 / 分割 / 拆解 / 分段 / 子字串
int sscanf( const char *restrict buffer, const char *restrict format, ... );
int swscanf (const wchar_t* ws, const wchar_t* format, ...);
02.各種類型資料(int,float,double,…)轉換與字串格式化合併輸出
int sprintf( char *restrict buffer, const char *restrict format, ... );
int swprintf (wchar_t* ws, size_t len, const wchar_t* format, ...);
★code:
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
#include <locale.h>
#include <string.h>
#define LEN 80
/*
sscanf(swscanf)
支援集合操作:
%[a-z] 表示匹配a到z中任意字元,貪婪性(盡可能多的匹配)
%[aB'] 匹配a、B、'中一員,貪婪性
%[^a] 匹配非a的任意字元,貪婪性
*/
int main()
{
//*
//預設編碼環境設定:
//Setting -> Editor ->Global compiler settings->Other options -> default
//Build options->compiler settings->Other options []
char Info[]="Dec 12/25 School ClassRoom123456789";
char Data1[16];
char Data2[16];
char Data3[50];
sscanf(Info, "%s%s%s", Data1, Data2,Data3);//預設 空格 切割
printf("Data1:%s Data2:%s Data3:%s\n", Data1, Data2, Data3);
sscanf(Info, "%[^ ] %[^ ] %[^ ]", Data1, Data2,Data3);//正規 空格 切割
printf("Data1:%s Data2:%s Data3:%s\n", Data1, Data2, Data3);
sscanf(Info, "%s%s %[a-z A-Z]", Data1, Data2,Data3);//正規空格+英文切割
printf("Data1:%s Data2:%s Data3:%s\n", Data1, Data2, Data3);
sscanf(Info, "%s%s %[a-z A-Z 0-9]", Data1, Data2,Data3);//正規空格+[英文&數字]切割
printf("Data1:%s Data2:%s Data3:%s\n", Data1, Data2, Data3);
printf("\n");
char name[20], tel[50], field[20], areaCode[20], code[20];
int age;
sscanf("name:jashliao age:40 tel:082-313530", "%s", name);//預設 空格 切割
printf("%s\n", name);
sscanf("name:jashliao age:40 tel:082-313530", "%8s", name);//預設 空格+限制長度8 切割
printf("%s\n", name);
sscanf("name:jashliao age:40 tel:082-313530", "%[^:]", name);//冒號 切割
printf("%s\n", name);
sscanf("name:jashliao age:40 tel:082-313530", "%[^:]:%s", field, name);//冒號+符號對應+空白 切割
printf("%s %s\n", field, name);
sscanf("name:jashliao age:40 tel:082-313530", "name:%s age:%d tel:%s", name, &age, tel);//符號(字元)對應+空白 切割
printf("%s %d %s\n", name, age, tel);
sscanf("name:jashliao age:40 tel:082-313530", "%*[^:]:%s %*[^:]:%d %*[^:]:%s", name, &age, tel);//冒號+空白 切割
printf("%s %d %s\n", name, age, tel);
printf("\n");
char buf[LEN];
sprintf(buf,
"%d %f %s %d %d %d %s",
25, 54.32E-1, "Thompson", 56, 789, 123, "56"
);
printf("%s", buf);
//*/
/*
//使用寬字串/UTF-8 環境設定:
//Setting -> Editor ->Global compiler settings->Other options -> UTF-8
//Build options->compiler settings->Other options [-finput-charset=UTF-8]
setlocale(LC_ALL, "");
wchar_t Info[]=L"Dec 12/25 School ClassRoom123456789";
wchar_t Data1[16];
wchar_t Data2[16];
wchar_t Data3[50];
swscanf(Info, L"%s%s%s", Data1, Data2,Data3);//預設 空格 切割
wprintf(L"Data1:%s Data2:%s Data3:%s\n", Data1, Data2, Data3);
swscanf(Info, L"%[^ ] %[^ ] %[^ ]", Data1, Data2,Data3);//正規 空格 切割
wprintf(L"Data1:%s Data2:%s Data3:%s\n", Data1, Data2, Data3);
swscanf(Info, L"%s%s %[a-z A-Z]", Data1, Data2,Data3);//正規空格+英文切割
wprintf(L"Data1:%s Data2:%s Data3:%s\n", Data1, Data2, Data3);
swscanf(Info, L"%s%s %[a-z A-Z 0-9]", Data1, Data2,Data3);//正規空格+[英文&數字]切割
wprintf(L"Data1:%s Data2:%s Data3:%s\n", Data1, Data2, Data3);
wprintf(L"\n");
wchar_t name[20], tel[50], field[20], areaCode[20], code[20];
int age;
swscanf(L"name:一把梭 age:40 tel:082-313530", L"%s", name);//預設 空格 切割
wprintf(L"%s\n", name);
swscanf(L"name:一把梭 age:40 tel:082-313530", L"%8s", name);//預設 空格+限制長度8 切割
wprintf(L"%s\n", name);
swscanf(L"name:一把梭 age:40 tel:082-313530", L"%[^:]", name);//冒號 切割
wprintf(L"%s\n", name);
swscanf(L"name:一把梭 age:40 tel:082-313530", L"%[^:]:%s", field, name);//冒號+符號對應+空白 切割
wprintf(L"%s %s\n", field, name);
swscanf(L"name:一把梭 age:40 tel:082-313530", L"name:%ls age:%d tel:%s", name, &age, tel);//符號(字元)對應+空白 切割
wprintf(L"%s %d %s\n", name, age, tel);
swscanf(L"name:一把梭 age:40 tel:082-313530", L"%*[^:]:%s %*[^:]:%d %*[^:]:%s", name, &age, tel);//冒號+空白 切割
wprintf(L"%s %d %s\n", name, age, tel);
wprintf(L"\n");
wchar_t buf[LEN];
swprintf(buf,
L"%d %f %ls %d %d %d %s",
25, 54.32E-1, L"一把梭", 56, 789, 123, L"56"
);
wprintf(L"%s", buf);
//*/
return 0;
}
★結果:
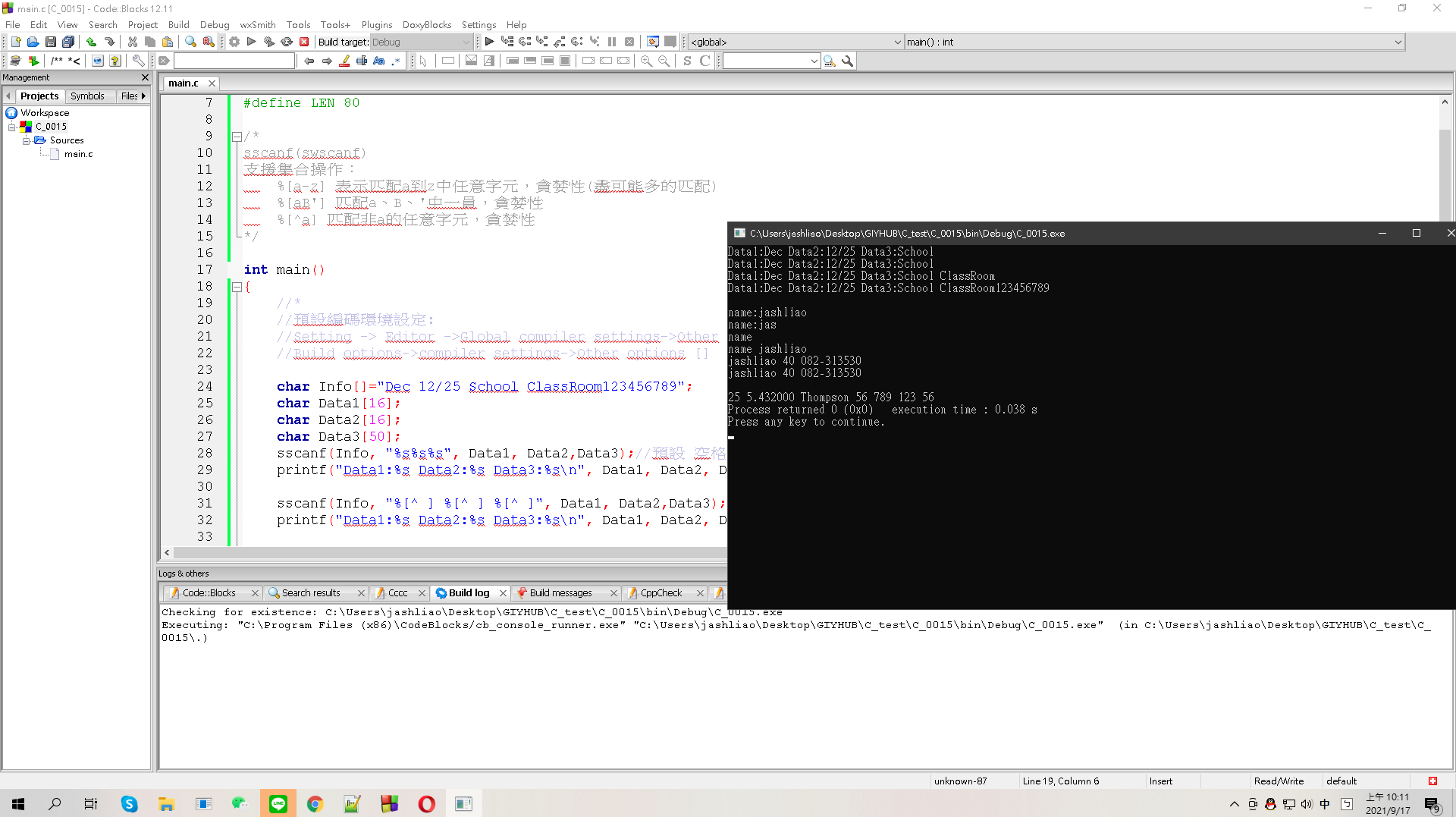
★延伸說明/重點回顧:
01.C語言的字串就是字元陣列
02.從函數介紹可以大致發現寬字串和標準字串函數用法觀念幾乎一致,其差別就只有函數名稱和參數型態
03.這些函數是為了進行『資料分析/資料清洗』和『資料組合』的前置動作,對於日後非常實用建議好好收藏
04.sscanf(swscanf)/sprintf(swprintf)用法剛好分別對應scanf(wscanf)/printf(wprintf),因此今天所有內容也完全可以應用與呼應到之前的文章
05.各種C/C++的函示庫: QT/BCB/VC++ 都有自己的類似函數,但是都和標準C語言類似,所以只要學會基礎要轉到其他的平台就很容易了
2 thoughts on “一把梭系列 ~ C語言範例 (0015) [字串的掃描與格式化]”
YOUTUBE URL: https://youtu.be/TtuEygCjsRM
C/C++ 字串 分割 切割 拆解 拆分 分解 解析