

很令人訝異的事情是,當被問及「你現在編輯的原始碼檔案是什麼編碼?」,不少程式設計人員都答不出來。
如果在正體中文 Windows 中開一個純文字檔案,用「記事本」編輯的話,應該是用 MS950 來處理原始碼中字元的儲存,現在許多 Linux 系統,預設使用 UTF-8 編碼,所以在這些 Linux 直接使用 vim 等編輯器編輯原始碼的話,預設應該就是 UTF-8。
如果是在整合開發環境(IDE)中,要視 IDE 的設定,有些 IDE 預設是使用作業系統編碼,有些 IDE 預設使用 UTF-8,如果在 IDE 中,預設是用 Big5 的編輯器,結果開啟 UTF-8 的原始碼,也會是亂碼,你必須指定編輯器使用正確的編碼來開啟原始碼。
這有什麼問題呢?以 Java 而言,在正體中文 Windows 中,如果用舊版記事本編輯原始碼:
public class Main {
public static void main(String[] args) {
System.out.println("哈囉!世界!");
}
}
如果直接如下編譯:
C:\workspace>javac Main.java
那麼就會編譯成功,不過,編譯器是使用哪種編碼來解譯原始碼呢?答案是作業系統預設編譯,正體中文 Windows 中,如果用記事本編輯原始碼,原始碼檔案預設用 MS950 儲存,而編譯器採用作業系統編碼編譯,所以就不用任何指定,就可以正確編譯。
同樣地,在預設編碼為 UTF-8 的 Linux 中,如果你用 vim 編輯原始碼,原始碼檔案是用 UTF-8 儲存,而編譯器採用作業系統編碼編譯,所以就不用任何指定,就可以正確編譯。
如果用記事本轉存為「Unicode」或「Unicode big endian」編碼,那要如何編譯?答案是指定 -encoding 告知編譯器原始檔案的編碼:
C:\workspace>javac -encoding UTF-16 Main.java
如果用舊記事本轉存為「UTF-8」編碼,那要如何編譯?答案是無法編譯,即使指定了 -encoding 為 UTF-8 也一樣…
C:\workspace>javac -encoding UTF-8 Main.java
Main.java:1: illegal character: \65279
?public class Main {
^
1 error
在 UTF-8 中談過,因為 Windows 的記事本存成 UTF-8 時,會在檔首加上 BOM,javac 編譯器並不處理BOM,只會視為不合法字元,如果要將原始碼存為 UTF-8,必須使用可存為檔首無BOM的編譯器,例如 NotePad++。
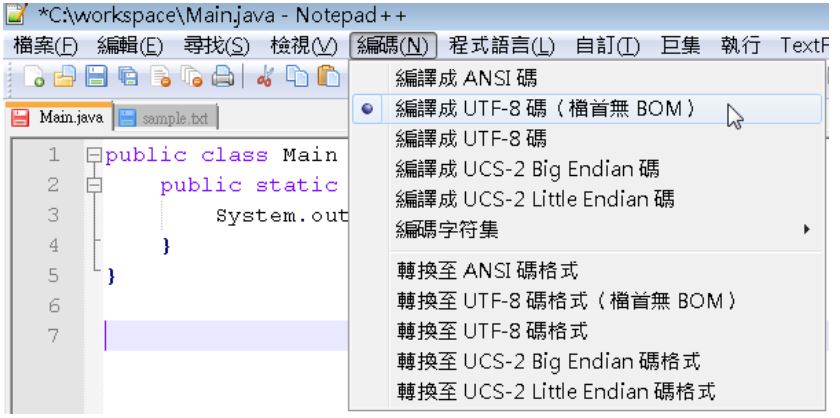
如此指定 -encoding 為 UTF-8 進行編譯,就可以編譯成功(新版 Windows 記事本已經預設使用檔首無 BOM 的 UTF-8 儲存)。
在 Windows 中,如果用 gcc 編譯一個以 Big5 儲存的 C 原始碼:
#include <stdio.h>
int main(void) {
printf("編譯成功");
return 0;
}
可能會得到錯誤訊息:
C:\workspace>gcc main.c
main.c: In function `main':
main.c:4: error: missing terminating " character
main.c:5: error: syntax error before "return"
如果將原始碼中的「成功」改為「OK」,編譯就會成功,為什麼?檢視原始碼的十六進位碼:
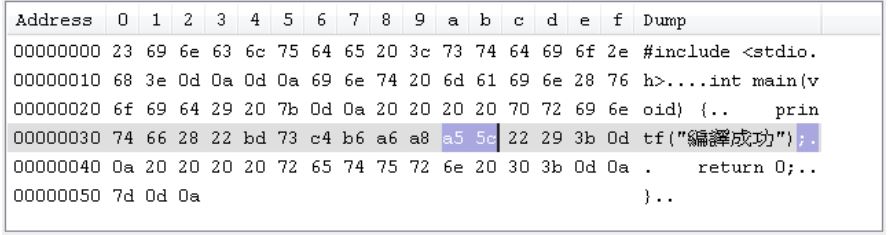
「功」這個字儲存為 a5、5c 兩個位元組,而 5C 在 ASCII 字元表中,就是 \ 字元,也就是說,gcc 看到了 \ 字元,以為是略過(escape)字元,但下一個字元是 ",結果組成了 \",因此 gcc 以為 " 沒有成對,因此編譯失敗,這就是過去著名的「許功蓋」問題。
如果將 C 原始碼存為 UTF-8 再直接編譯,執行結果會出現亂碼:
C:\workspace>gcc main.c
C:\workspace>a
蝺刻陌?栀?
只是將字元的位元組改為另一組位元,所以編譯可以成功,但執行時 Windows 的 Console 預設使用 MS950(也就是 Big5 相容),對這組位元並沒有對應實際可辨識的字元,所以就是亂碼,必須如下指定執行時期編碼為 Big5:
C:\workspace>gcc -fexec-charset=BIG5 main.c
C:\workspace>a
編譯成功
新版的 Windows 10 可以藉由地區設定,將 Console 預設為 UTF-8:
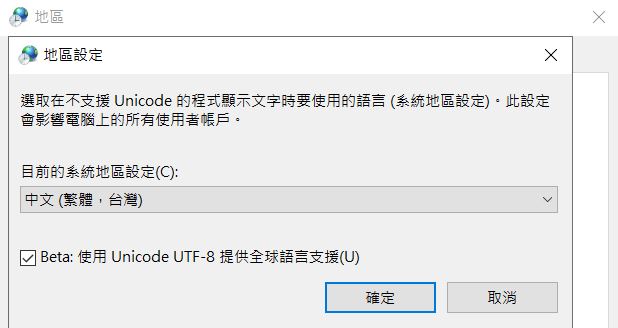
不同語言辨識或指定原始碼編碼的方式並不相同,可以進一步參考:
甚至在不同環境中也會有不同方式,可參考: