

如果在正體中文 Windows 中,使用以下的程式來讀取內含「測試」文字的檔案:
package cc.openhome;
import static java.lang.System.out;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try(BufferedReader reader = new BufferedReader(new FileReader("sample.txt"))) {
out.println(reader.readLine());
}
}
}
如果文字檔案是使用 MS950 儲存,那上面的程式在命令提示字元中,可以正確讀出並顯示「測試」,如果文字檔案不是 MS950,就會顯示亂碼,例如,假設是 UTF-8 儲存「測試」的文字檔案:
C:\workspace>java cc.openhome.Main
皜祈岫
有些 API 若不指定編碼,通常會使用 JVM 預設編碼,預設會與作業系統預設編碼相同,像是 String 建構式、 getBytes() 方法或這邊看到的 FileReader 等(其他還有 java.io、java.util、java.net 等套件中的一些 API),可以使用 Charset.defaultCharset() 取得預設編碼。
在啟動 JVM 時,其實可以使用 -Dfile.encoding 指定 JVM 預設編碼,例如:
C:\workspace>java -Dfile.encoding=UTF-8 cc.openhome.Main
也可以使用 InputStreamReader,將讀入的位元組指定編碼進行字串轉換。例如:
package cc.openhome;
import static java.lang.System.out;
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try(BufferedReader reader = new BufferedReader(
new InputStreamReader(
new FileInputStream("sample.txt"), "UTF-8"));) {
out.println(reader.readLine());
}
}
}
System.out 在輸出字串時,若是出現亂碼,可能的原因之一是,System.out 採用的編碼與連結的標準輸出不對應,基本上,System.out 採用 JVM 預設編碼,若 JVM 預設編碼為 Big5,System.out 就採用 Big5,此時若連結的標準輸出採用 UTF-8 的話,就會產生亂碼,這時可以透過 System.setOut() 結合 PrintStream 來設定編碼:
System.setOut(new PrintStream(System.out, true, "UTF-8"));
這類情況常發生在 IDE 之中,例如,在 Eclipse 中,若執行時設定的主控台編碼設定為 Big5(可在 Run As/Run Configurations/Common 中設定),然而 System.out 採用 JVM 預設編碼為 UTF-8,輸出文字時就會是亂碼,反之亦然。
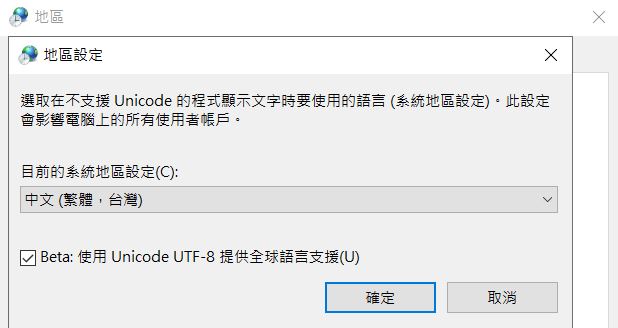
如果命令提示字元採用的是 Big5,遇到 Big5 以外的字元,顯示上就會出現亂碼,這時必須調整命令提示字元編碼,並且配合正確的字型設定,才能正確顯示字元,例如,在〈你的原始碼是什麼編碼?〉中談到的,新版的 Windows 10 可以藉由地區設定,將 Console 預設為 UTF-8:
在較新版的 JDK 中,有些 API 直接採用 UTF-8 為預設編碥,而不是根據 JVM 預設編碼,例如 Files.readAllLines()、Files.newBufferedReader() 等。
在撰寫這篇文件的時間點上,有個〈JEP draft: Use UTF-8 as default Charset〉建立於 2017/08/31,提議未來 JDK 直接將 UTF-8 作為 JVM 預設編碼。