

如果想使用者輸入的手機號碼格式是否為 XXXX-XXXXXXX,其中 X 為數字,雖然規則表示式可以使用 \d\d\d\d-\d\d\d\d\d\d,不過更簡單的寫法是 \d{4}-\d{6},{n} 是貪婪量詞(Greedy quantifier)表示法的一種,表示前面的項目出現 n 次。
底下列出可用的貪婪量詞:
X?:X 項目出現一次或沒有X*:X 項目出現零次或多次X+:X 項目出現一次或多次X{n}:X 項目出現 n 次X{n,}:X 項目至少出現 n 次X{n,m}:X 項目出現 n 次但不超過 m 次
貪婪量詞之所以貪婪,是因為看到貪婪量詞時,比對器(Matcher)會把符合量詞的文字全部吃掉,再逐步吐出(back-off)文字,看看是否符合貪婪量詞後的規則表示式,如果吐出的部份也符合就比對成功。
簡單來說,貪婪量詞會儘可能地找出長度最長的符合文字。
例如文字 xfooxxxxxxfoo,若使用規則表示式 .*foo 比對,比較器根據 .* 吃掉了整個 xfooxxxxxxfoo,之後吐出 foo 符合 foo 部份,得到的符合字串就是整個 xfooxxxxxxfoo。
若在貪婪量詞表示法後加上 ?,會成為逐步量詞(Reluctant quantifier),又常稱為懶惰量詞,或非貪婪(non-greedy)量詞(相對於貪婪量詞來說),比對器是一邊吃一邊比對文字是否符合量詞與之後的規則表示式。
簡單來說,逐步量詞會儘可能地找出長度最短的符合文字。
例如文字 xfooxxxxxxfoo 若用規則表示式 .*?foo 比對,比對器在吃掉 xfoo 後發現符合 .*? 與 foo,接著繼續吃掉 xxxxxxfoo 發現符合 .*? 與 foo,得到 xfoo 與 xxxxxxfoo 兩個符合文字。
有些工具或語言支援獨吐量詞(Possessive quantifier),例如 Java(然而 Python、JavaScript 不支援),也就是在貪婪量詞表示法後加上 +,比對器會將符合量詞的文字全部吃掉,而且不再回吐(因此才稱為獨吐)。
例如文字 xfooxxxxxxfoo,若使用規則表示式 x*+foo 比對,x 符合 x*+ 被吃了,後續 foo 符合 foo,得到 xfoo 符合,接著 xxxxxx 符合 x*+ 被吃了,後續 foo 符合 foo,得到 xxxxxxfoo 符合。
文字 xfooxxxxxxfoo,若使用規則表示式 .*+foo 比對,整個 xfooxxxxxxfoo 會因符合 .*+ 全被比對器吃了,沒有文字可再用於比對 foo,結果就是沒有任何文字符合。
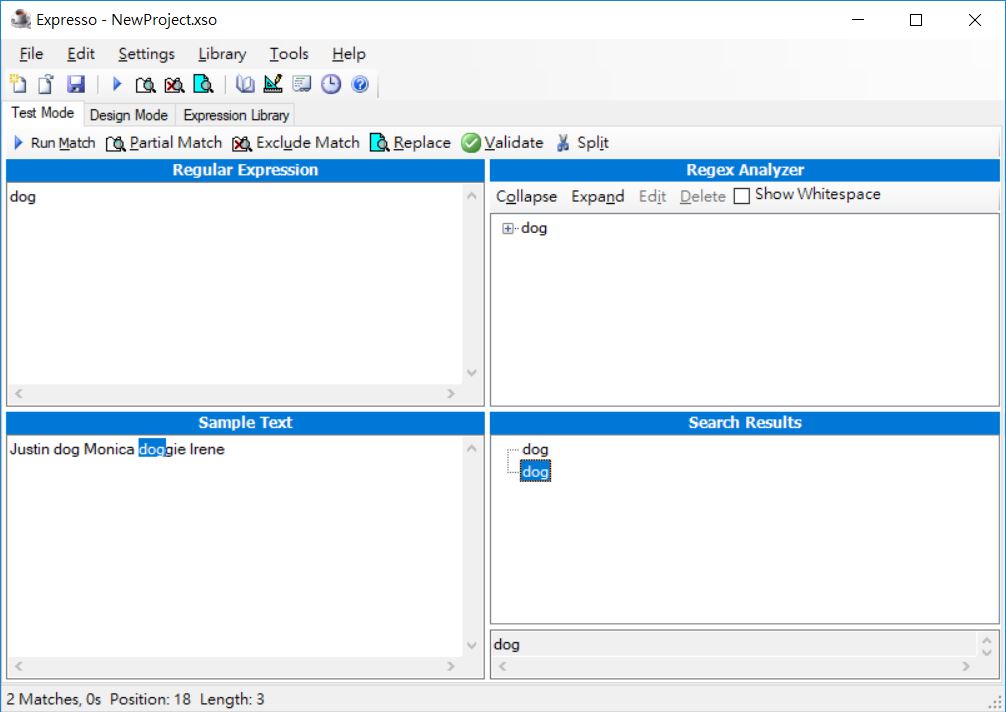
如果有個文字 Justin dog Monica doggie Irene,使用表示式 dog 的話,會符合到 dog 與 doggie 前的 dog 部份:
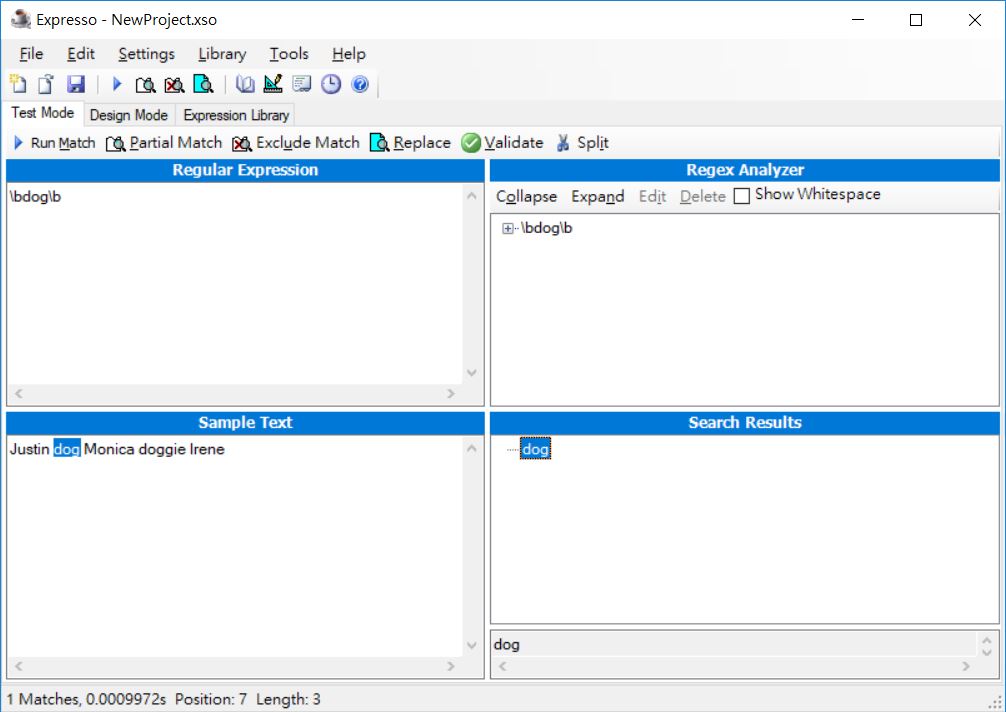
你可以使用 \b 標出單字邊界,例如 \bdog\b,這就只會比對出 dog 單字:
邊界比對用來表示文字必須符合指定的邊界條件,也就是定位點,因此這類表示式也常稱為錨點(Anchor),底下列出規則表示式中可用的邊界比對:
^:一行開頭$:一行結尾\b:單字邊界\B:非單字邊界\A:輸入開頭\G:前一個符合項目結尾\Z:非最後終端機(final terminator)的輸入結尾\z:輸入結尾