

由於 Big5 用第一個位元組的某個範圍來作為識別是否為中文字,可儲存的文字範圍就大大減少(約為一萬九千多個),如果儲存的字元,不在 Big5 / MS950 編碼範圍內,那會如何?
如果是 Windows 舊版的記事本程式,會出現以下的提示,要你轉存為 Unicode 格式:
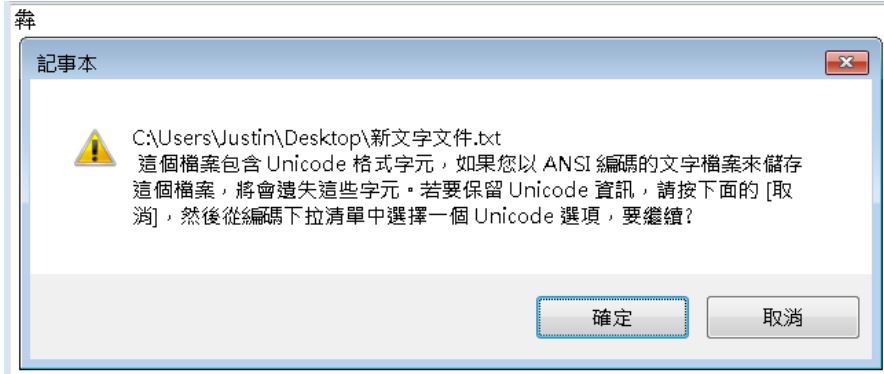
在按下「取消」後,會出現「另存新檔」的對話框,在右下會有個「編碼」選項,下拉的話,會有 Unicode、Unicode big endian 與 UTF-8 三個選項。
Unicode 是由 The Unicode Consortium 非營利組織所主導的編碼標準,它是一個字元對應一個數字的映射,這個數字稱之為碼點(Code point),在表達字元對應的碼點時,於「U+」之後接著一組十六進位數字來表示字元的碼點,如果使用四個十六進位制數字,可以表達六萬多個字元,如果使用五或六個十六進位制,可以表達更多的字元。
Unicode 字元映射至數字的概念編碼(Conceptual encoding),一個字元的 Unicode 碼點是固定的,而這個數字在電腦中如何用位元組來實作則有不同的方式,Unicode 的實作方式就稱為 Unicode/UCS Transformation Format,簡稱 UTF。
如果直接將方才的範例選擇「Unicode」儲存,用十六進位檢視會看到:

「犇」這個字的 Unicode 碼點是 U+7287,對於 Windows 的記事本若選擇使用「Unicode」儲存,則使用兩個位元組來儲存,Windows 的記事本選擇「Unicode」選項時,實際上採用 UCS-2/UTF-16 儲存(UTF-16 是 UCS-2 的後續者,兩者差異對語言會有影響,實例之一可參考《Effective JavaScript》條款七),一開頭的兩個位元組(ff fe)是用來識別檔案採用的位元組順序,稱為 BOM(byte order mark),之後使用兩個位元組來儲存每個 Unicode 字元。
要注意的是, 「犇」這個字的 Unicode 碼點是 U+7287,實際儲存時的位元組卻是 87、72,也就是說,Windows 記事本選擇「Unicode」儲存兩個以上位元組的資料時,是先存低位元組,再存高位元組,這樣的儲存方式,是採 Little Endian 的方式,也就是 Windows 記事本選擇「Unicode」時,實際上採用的是 UCS-2/UTF-16 Little Endian。
Unicode 指定 BOM 編碼為 U+FEFF。如果讀取檔案開頭的 BOM 是 0xfeff,表示檔案採用 Big Endian,如果讀取檔案開頭的 BOM 是 0xfffe,表示檔案採用 Little Endian。
如果使用 Windows 記事本儲存時的選項是「Unicode big endian」,同樣儲存「犇」,結果會如下:

可以看到,用來表示為 Unicode 檔案的兩個位元組為 fe、ff,與先前 的ff、fe 相反,而「犇」這個字現在儲存為 72、87,與先前的 87、72 也是相反。如果儲存兩個以上位元組資料時,採先存高位元,再存低位元方式,則這樣的儲存方式,是採 Big Endian 的方式。
這會有什麼影響?如果使用以下的 Java 程式來讀取一個存有「這T是e個s測t試」的文字檔案:
package cc.openhome;
import java.nio.file.Files;
import java.nio.file.Paths;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) throws Exception {
byte[] bytes = Files.readAllBytes(Paths.get("sample.txt"));
for(int i = 0; i < bytes.length; i += 2) {
byte[] data = {bytes[i], bytes[i + 1]};
out.printf("%-5h", toInt(data));
out.println(new String(data, "UTF-16"));
}
}
public static int toInt(byte[] bytes) {
return ((bytes[0] << 8) | (bytes[1] & 0xFF)) & 0XFFFF;
}
}
若文字檔案採 Windows 記事本中的「Unicode」選項儲存,那麼會得到亂碼:
fffe
1990 ?
5400 ?
2f66 ?
6500 攀
b50 ?
7300 猀
2c6e ?
7400 琀
668a 暊
如果存有「這T是e個s測t試」的文字檔案,是使用 Windows 記事本「Unicode big endian」選項儲存,也就是採 UCS-2/UTF-16 Big Endian,以上程式可以得到正確的文字顯示:
feff
9019 這
54 T
662f 是
65 e
500b 個
73 s
6e2c 測
74 t
8a66 試
這是因為 JVM 本身是採 Big Endian 的方式來處理位元組,對於一個文字檔案採 Windows 記事本中的「Unicode」選項儲存,則是採 Little Endian,用以上的程式讀取當然會是亂碼,如果要正確讀取 Windows 記事本中的「Unicode」選項儲存的文字檔案,方法之一是在 Java 中要自行調換位元組順序:
package cc.openhome;
import java.nio.file.Files;
import java.nio.file.Paths;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) throws Exception {
byte[] bytes = Files.readAllBytes(Paths.get("sample.txt"));
for(int i = 0; i < bytes.length; i += 2) {
byte[] data = {bytes[i + 1], bytes[i]}; // 調換順序
out.printf("%-5h", toInt(data));
out.println(new String(data, "UTF-16"));
}
}
public static int toInt(byte[] bytes) {
return ((bytes[0] << 8) | (bytes[1] & 0xFF)) & 0XFFFF;
}
}
或者是指定使用 UTF-16LE,例如:
package cc.openhome;
import java.nio.file.Files;
import java.nio.file.Paths;
import static java.lang.System.out;
public class Main {
public static void main(String[] args) throws Exception {
byte[] bytes = Files.readAllBytes(Paths.get("sample.txt"));
for(int i = 0; i < bytes.length; i += 2) {
byte[] data = {bytes[i], bytes[i + 1]};
out.printf("%-5h", toInt(data));
out.println(new String(data, "UTF-16LE")); // 指定 UTF-16LE
}
}
public static int toInt(byte[] bytes) {
return ((bytes[0] << 8) | (bytes[1] & 0xFF)) & 0XFFFF;
}
}
這個範例的執行結果會是:
fffe ?
1990 這
5400 T
2f66 是
6500 e
b50 個
7300 s
2c6e 測
7400 t
668a 試