

〈參考〉中談到,參考是物件的別名,在 C++ 中,「物件」這個名詞,不單只是指類別的實例,而是指記憶體中的一塊資料,那麼可以參考字面常量嗎?常量無法使用 & 取址,例如無法 &10,因此以下會編譯錯誤:
int &r = 10; // error: cannot bind non-const lvalue reference of type 'int&' to an rvalue of type 'int'
不過,加上 const 的話倒是可以:
const int &r = 10;
常量是記憶體中臨時的資料,無法對常量取址,因此編譯器會將以上轉換為像是:
const int _n = 10;
const int &r = _n;
實際上,r 並不是真的參考至 10,而是 10 被複製給 _n,然後 r 參考至 _n,如果不加上 const,那麼你可能會以為變更了 r,就是變更了 10 位址處的值,因此就要求你一定得加上 const,不讓你改了。
為什麼會需要參考至常量?通常跟函式呼叫相關,這之後文件再來討論;類似地,以下會編譯失敗:
int a = 10;
int b = 20;
int &r = a + b; // error: cannot bind non-const lvalue reference of type 'int&' to an rvalue of type 'int'
這是因為 a + b 運算出的結果,會是在臨時的記憶體空間中,無法取址;類似地,若想通過編譯,必須加上 const:
int a = 10;
int b = 20;
const int &r = a + b;
不過在 C++ 11 之後,像以上的運算式,可以直接參考了:
int a = 10;
int b = 20;
int &&rr = a + b;
在以上的程式中,int&& 是 rvalue 參考(rvalue reference),rr 參考了 a + b 運算結果的空間,相對於以下的程式來說比較有效率:
int a = 10;
int b = 20;
int c = a + b; // 將 a + b 的結果複製給 c
因為不必有將值複製、儲存至 c 的動作,效率上比較好,特別是當 rvalue 運算式會產生龐大物件的時候,複製就會是個成本考量,例如 s1、s2 若是個很長的 string,那麼 s1 + s2 的結果還會複製給目標 string 的話:
string result = s1 + s2;
改用以下會比較經濟:
string &&result = s1 + s2;
相對於 rvalue 參考,int& 這類參考就被稱為 lvalue 參考;只不過,lvalue 或 rvalue 是什麼?方才編譯錯誤的訊息中,似乎也出現了 lvalue、rvalue 之類的字眼,這些是什麼?
lvalue、rvalue 是 C++ 對運算式(expression)的分類方式,一個粗略的判別方式,是看看 & 可否對運算式取址,若可以的話,運算式是 lvalue,否則是個 rvalue。
若要精確的定義,可以參考〈Value categories〉,該文件中 History 的區段,有談到運算式分類的歷史,最早是從 CPL 開始對運算式區分為左側模式(left-hand mode)與右側模式(right-hand mode),左、右是指運算式是在指定的左或右側,有些運算式只有在指定的左側才會有意義。
C 語言有類似的分類方式,分為 lvalue 與其他運算式,l 似乎暗示著 left 的首字母,不過實際上,並非以指定的左、右來分類,lvalue 是指可以識別物件的運算式,白話點的說法是,運算式的結果會是個有名稱的物件。
到了 C++ 98,非 lvalue 運算式被稱為 rvalue,一些 C 中非 lvalue 的運算式成了 lvalue,到了 C++ 11,運算式又被重新分類為〈Value categories〉中的結果。
許多文件取 lvalue、rvalue 的 l、r,將它們分別譯為左值、右值,就運算式的分類歷史來說,不能說是錯,不過嚴格來說,C++ 中 lvalue、rvalue 的 l、r,並沒有左、右的意思,lvalue、rvalue 只是個分類名稱。
在〈Value categories〉一開頭,可以看到目前的 C++ 標準,將運算式更細分為 glvalue、prvalue、xvalue、lvalue 與 rvalue,g 暗示為 generalized,pr 暗示為 pure,x 暗示為 eXpiring,就涵蓋關係而言,使用圖來表示會比較清楚:
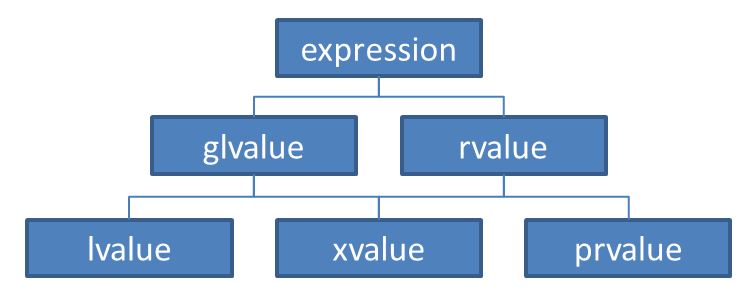
具體來說,哪個運算式屬於哪個分類,〈Value categories〉都有舉例,當然,容易看到眼花花…
方才談到,一個粗略的判別方式,是看看 & 可否對運算式取址,若可以的話,運算式是 lvalue,否則是個 rvalue;另一個白話點的判別方式是,lvalue 運算式的結果會是個有名稱的物件,例如 a,rvalue 的結果是暫時性存在於記憶體,例如 a + b。
那麼 ++i、i++ 呢?在〈遞增、遞減、指定運算〉中談過,++i 運算結果是遞增後的 i,也就是 ++i 運算結果是個有名稱的物件,因此可以使用 lvalue 參考:
int i = 10;
int &r = ++i; // OK
然而 i++ 運算結果是遞增前的 i,暫時性存在於記憶體,若不指定給變數的話就不見了,因此 i++ 是個 rvalue,因此以下會編譯失敗:
int i = 10;
int &r = i++; // error: cannot bind non-const lvalue reference of type 'int&' to an rvalue of type 'int'
C++ 11 開始,若想參考 i++ 運算時暫時存在於記憶體中遞增前的 i,可以使用 rvalue 參考:
int i = 10;
int &&rr = i++; // OK
哪些是 lvalue,而哪些又是 rvalue,基本上還是以〈Value categories〉的定義為準,不清楚的話就查一下。
使用 rvalue 參考通常是為了效率上的考量,
還有個 std::move(定義於 utility 標頭檔)用來實現移動語義(move semantics),例如實現移動建構式(move constructor),這需要在認識類別定義、複製建構式等之後才能細談,就現階段而言,可以從 string 來稍微認識一下,例如,以下會將 s1 的資料複製給 s2:
string s2 = s1; // s1 是個 string,而這邊會複製 s1 的內容給 s2
若 s1 指定給 s2 後,就不再會用到原本的內容,那麼複製就是不必要的成本,若能把 s1 的內容直接移給 s2 的話就好了,C++ 11 開始可以這麼做:
string s2 = std::move(s1);
這麼一來,s1 的資料就被移至 s2 了,在這之後不能立即使用 s1 來取值,因為資料轉移出去了,取值結果是不可預期的,只能銷毀 s1,或者是重新指定字串給 s1。
來看個簡單的示範:
#include <iostream>
#include <string>
using namespace std;
int main() {
string s1 = "abc";
string s2 = s1; // 複製 s1 的資料
cout << s1 << endl; // 顯示 "abc"
cout << s2 << endl; // 顯示 "abc"
}
跟移動版本比較一下:
#include <iostream>
#include <string>
#include <utility>
using namespace std;
int main() {
string s1 = "abc";
string s2 = std::move(s1); // 轉移 s1 的資料
// cout << s1 << endl; // 這時取值結果不可預期
cout << s2 << endl; // 顯示 "abc"
s1 = "xyz"; // OK
cout << s1 << endl; // 這時可以取值
}
移動版本之所以能夠運作,是因為 string 的建構式之一,使用了 rvalue 參考,而 std::move 的作用,其實是告訴編譯器,將指定的 lvalue 當成是 rvalue(某些程度就是一種 cast),以選擇定義了 rvalue 參考的建構式,而建構式中實現了移動來源資料的演算。
因為 move 這個名稱太平凡了,為了避免名稱衝突,建議包含 std 名稱空間,也就是使用 std::move。