

程式大多在處理一組資料,依需求的不同,你需要不同的容器來管理資料,List 是有序、具索引的容器,除此之外,常用的資料容器還有集合(Set)與字典(Dictionary)等,這邊就先來探討與這兩種容器相關的 Data.Set 與 Data.Map 模組。
Data.Set 模組
集合不允許元素重複,一個 List 中若沒有重複的元素,某些程度就可以當作集合來看待,為了方便,最好是寫個 fromList,自動從指定的 List 中去除重複的元素:
module Set
(
fromList,
intersection,
union
) where
fromList :: Eq a => [a] -> [a]
fromList [] = []
fromList (x:xs) = x : fromList (filter (/= x) xs)
intersection :: Eq a => [a] -> [a] -> [a]
intersection xs1 xs2 = filter (`elem` xs2) xs1
union :: Eq a => [a] -> [a] -> [a]
union xs1 xs2 = filter (`notElem` xs2) xs1 ++ xs2
這個簡單的自訂模組也示範了交集、聯集的運算:

實際上,由於集合要能判斷重複元素,每次走訪都從 List 頭到尾,效率並不好,因此,最好能實作為具有排序能力的樹狀結構,例如,上面的 fromList,可以直接使用 Data.List 的 nub,也能達到相同功能,不過面對較長的 List,就會有效率的問題。
Haskell 的 Data.Set 模組就提供了相關功能,因為要能排序,要使用 Data.Set 的 fromList 等函式,你的元素必須是可排序的,也就是必須具有 Ord 的行為:
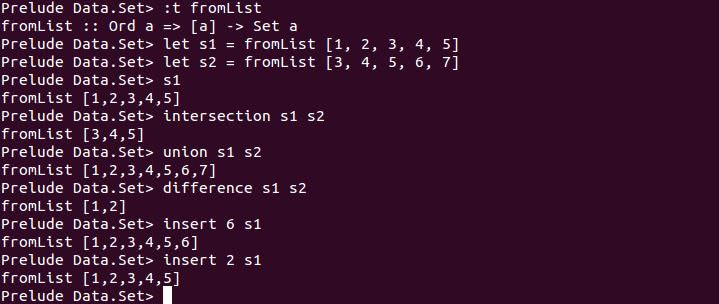
Data.Set 接受的元素必須具有 Ord 的行為,在於內部實作使用了樹狀結構,元素被加入樹時都會排序,因此,下個元素再加入時就可以很快地判定集合中是不是有重複元素,而不用像 nub 必須逐一對集合中的元素做相等比較,因此,對於較長的 List,想要取得不重複元素的 List,使用 Data.Set 的 fromList 後再用 toList,就可以得到,而且效率較好。
如果你想快速地瞭解這個模組還有哪些常用函式可以使用,可以參考 Data.Set。
Data.Map 模組
在〈Haskell Tutorial(17)定義與使用模組〉中,稍微探討過 Map 的實作:
module Map
(
Map,
empty,
fromList,
findValue
) where
data Map k v = Empty | Cm (k, v) (Map k v)
empty = Empty
fromList :: [(k, v)] -> Map k v
fromList [] = Empty
fromList (x:xs) = Cm x (fromList xs)
findValue :: (Eq k) => k -> Map k v -> Maybe v
findValue key Empty = Nothing
findValue key (Cm (k, v) xm) =
if key == k then Just v else findValue key xm
這個實作的出發點在於,可以使用 List,而其中元素為 (k, v) 的 Tuple 來模擬 Map,之後再定義專屬型能,當然,這個實作是很簡單的,第一,它沒有檢查鍵(Key)可能重複的情況,第二,findValue 每次都逐一走訪每個元素,效率並不好。
Data.Map 模組提供了字典(Dictionary)操作的相關功能,內部實作是樹狀結構,你的鍵必須具有 Ord 的行為,下面的示範,因為 lookup 方法會有名稱衝突,因此使用了 import qualified Data.Map as Map:
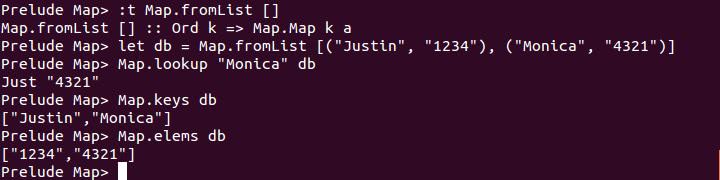
如果你想快速地瞭解這個模組還有哪些常用函式可以使用,可以參考 Data.Map。
既然談到了樹狀結構,最後來出個題目,試著實作一個 Tree 型態,並提供 fromList 函式可從 List 建立樹、insert 函式可將指定數值插入樹、node 函式可測試某節點是否在樹中、toList 可將樹轉為 List,例如:
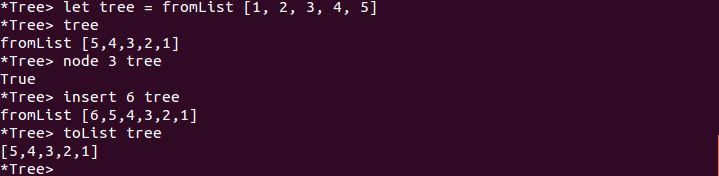
進一步地,你可以試著改用以上自訂的樹,改寫先前的 Set 模組實作嗎?